目次
CM1 – A Dataset for Evaluating Few-Shot Information Extraction with Large Vision Language Models
この論文は、少量の訓練データでの情報抽出能力を評価するために設計されたCM1データセットを提案し、大規模な視覚言語モデルの有効性を示しています。
この論文の特徴は、手書き文書からの情報抽出に特化した新しいデータセットCM1を用いて、大規模ビジョン言語モデルが少数のトレーニングサンプルでも従来の手法を上回る性能を示すことを実証した点です。
論文:https://arxiv.org/abs/2505.04214

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
手書き文書からのキー・バリュー情報の自動抽出は、文書分析における重要な課題です。信頼性のある抽出は、多くのアーカイブの大規模なデジタル化 efforts の前提条件です。大規模ビジョン言語モデル(LVLM)は、特に注釈付きトレーニングデータがほとんどないシナリオでこの問題に取り組むための有望な技術です。
本研究では、LVLMの少数ショット機能を評価するために特別に設計された新しいデータセットを提示します。CM1文書は、第二次世界大戦後のケアとメンテナンスプログラムを管理するために作成された手書きのエントリを含む歴史的なフォームのコレクションです。このデータセットは、名前と生年月日情報の抽出に関する3つのベンチマークを確立し、さらに異なるトレーニングセットサイズを考慮しています。
私たちは2つの異なるLVLMのベースライン結果を提供し、確立されたフルページ抽出モデルと性能を比較します。従来のフルページモデルは非常に競争力のあるパフォーマンスを達成しますが、我々の実験は、トレーニングサンプルがわずかしかない場合に、考慮されたLVLMがそのサイズと重い事前トレーニングから利益を得て、従来のアプローチを上回ることを示しています。
1. はじめに
19世紀から20世紀にかけて、フォームや登録カードは多くの行政プロセスの基盤となっていました。手書きエントリを含む機械印刷フォームが大量に作成され、多くのアーカイブが物理的形式で膨大な文書コレクションを保存していますが、そこに含まれる情報は大部分がアクセス不能な状態です。これらのコレクションのデジタル化は非常に望ましいことです。保存に加えて、人文科学の研究者たちは量的手法に基づいた歴史的・社会的発展の分析に強い関心を持っています。数百万の文書を含むコレクションの情報を統計的に分析するためには、自動抽出方法が不可欠です。
2. CM1データセット
2.1 データ準備
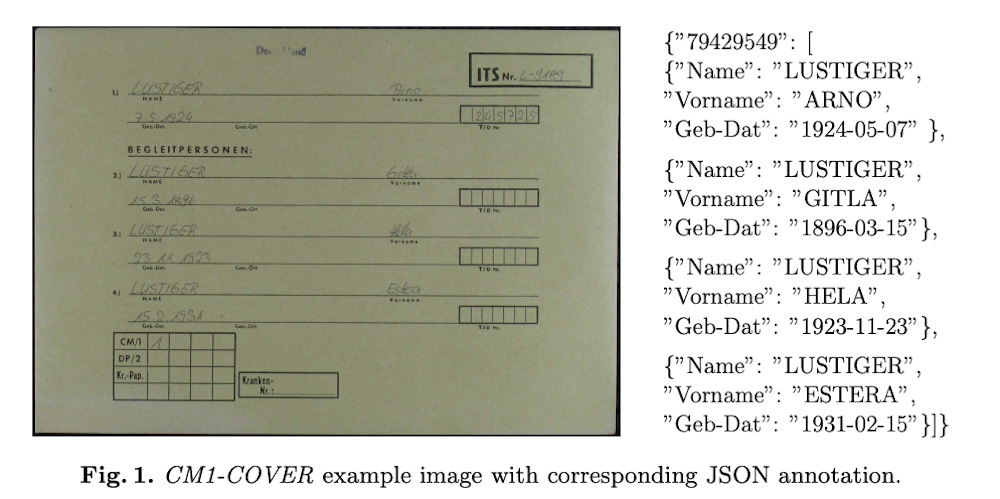
CM1文書はArolsen Archivesから提供され、支援申請に関連するすべての文書を表すプロセス識別子で整理されています。カバーページは同一レイアウトで、申請者と最大3名の同伴者に関する情報(名前、生年月日、出生地)を提供します。機械印刷フォームに手書きエントリが記載されており、フォーマットと筆跡は明瞭で劣化はほとんどありません。データセットは自己エンコーダを用いて視覚的特性を表す特徴抽出と、kmeans法によるクラスタリングを経て精選されました。
2.2 タスク
我々は、全ページ情報抽出のための3つのベンチマークを提案します:CM1-COVER、CM1-NAME、CM1-DATEです。
CM1-COVERはカバーページに基づいており、人々のリストとそれに対応する生年月日を抽出するタスクです。予想される出力はJSON形式の文字列です。情報を抽出するために、モデルはセグメンテーションや手書き認識などの複数のタスクを実行する必要があります。
CM1-NAMEは申請書から抽出した単一ページに基づいており、主な申請者の氏名を抽出することが目的です。文書理解における主な課題は、名と姓が連続して現れないことがあるということです。
CM1-DATEは主な申請者の生年月日の抽出を目的としています。文書には複数の日付が含まれており、どの日付が主な申請者を参照しているかを識別することが重要な課題です。
3. 全ページ情報抽出
従来の情報抽出は、テキスト検出、レイアウト分析、テキスト認識などの独立コンポーネントによる順次パイプラインを採用していますが、エラー伝播の課題があります。対照的に、DONUTやLVLMなどのエンドツーエンドモデルは単一アプローチでこれらの工程を統合し、エラー伝播を減少させます。
3.1 DONUT
Document Understanding Transformer(DONUT)は、全ページ情報抽出に特化したTransformerベースのエンコーダ-デコーダモデルです。DONUTのアーキテクチャは、エンコーダとしてSwin Transformerを、デコーダとしてBARTモデルを使用しています。Swin Transformerは階層的な特徴抽出アプローチを採用し、シフトされたウィンドウを使用して文書画像からローカルおよびグローバルな視覚的特徴の両方を効果的に捉えます。この能力は高解像度入力の処理と複雑な文書レイアウトの管理に不可欠です。BARTデコーダは自己回帰的テキスト生成アプローチを使用し、DONUTが生の文書画像からJSON形式のキーバリューペアなどの構造化出力を生成することを可能にします。
3.2 PaliGemma
PaliGemma3Bは、SigLIP-So400mビジョンエンコーダをGemma-2B言語モデルと統合したオープンウェイトLVLMで、約30億のパラメータを持っています。アーキテクチャはViTエンコーダを使用して入力画像を処理し、高次元の視覚的特徴を抽出し、それらをGemma-2B言語モデルの入力空間に一致するように線形に投影します。この統合アーキテクチャにより、モデルは視覚的理解と自然言語生成の両方を必要とするタスクを効果的に処理することができます。
3.3 Qwen2.5-VL
Qwen2.5-VLは、ViTとQwen2.5 LLMを組み合わせた完全にTransformerベースのアーキテクチャに基づく最先端のLVLMです。エンコーダは動的解像度ViTとウィンドウアテンションを使用しており、モデルが様々な入力画像サイズを効率的に処理し、可変数のビジョントークンを生成することを可能にします。この動的画像解像度により、Qwen2.5-VLは複雑な文書を解釈し、詳細な視覚情報を抽出する際に特に有益なネイティブ解像度で画像を処理することができます。視覚トークンの埋め込みはクロスモーダルアテンションによってLMMの入力サイズに適応されます。
3.4 トレーニング(PEFT)
両方のLVLMを歴史的文書理解の特定要件に適応させるために、我々はParameter Efficient Fine-Tuning(PEFT)技術、特にLow-Rank Adaptation(LoRA)とQuantized LoRA(QLoRA)を採用しています。LoRAは様々なタスクにわたりLLMの完全微調整に対する強力な近似を示し、計算メモリの要求を大幅に削減しながら比較可能なパフォーマンスを達成しています。LVLMのトレーニングに低ランク行列を導入することで、LoRAはパラメータのサブセットのみを変更することにより効率的な微調整を可能にします。QLoRAはさらに量子化技術を適用して、低精度重み表現によってメモリフットプリントを削減し、効率を高めます。これらのアプローチは計算コストを大幅に削減し、単一GPUセットアップでの微調整を可能にし、リソース制約のある環境での高性能LVLMへのアクセスを広げます。
4. 実験
4.1 トレーニングセットアップ
トレーニングは80GB VRAMを搭載した単一のNVIDIA A100 GPUで実施され、大規模モデルの微調整に十分な計算リソースを確保しました。我々はAdamW最適化器を使用し、PaliGemmaとQwen2.5-VLには1e-4の初期学習率を、DONUTには3e-5の学習率を適用しました。トレーニングが進むにつれて学習率を徐々に減少させるコサイン減衰学習率スケジュールに従いました。
4.2 メトリクス
提案したベンチマークでのモデルパフォーマンスを評価するために、我々は文字誤り率(CER)、精度、ツリー編集距離(TED)を使用しています。CERは抽出されたテキストと正解テキスト間の文字レベルの編集距離を測定します。低いCER値はより良いテキスト認識性能を示し、0%のCERは完璧な抽出を意味します。
精度は正解とちょうど一致する正しく抽出されたエンティティ(例:氏名、生年月日)の割合を評価します。このメトリクスは部分的な抽出の正確性が不十分である実世界のアプリケーションにとって特に重要です。
TEDはCM1-COVERの品質評価に使用され、抽出された構造化情報が期待されるフォーマットにどれだけ一致するかを測定します。
4.3 結果
評価の結果、以下の主要な知見が得られました:
- DONUTは少量データでは苦戦するが、データ量増加で性能が向上し、全データでは最良の結果を達成。
- LVLMは事前学習の恩恵により1%データでも強い少数ショット能力を示す。
- Qwen2.5-VLは特にCM1-NAMEとCM1-DATEの低データ設定で最高性能。
- ゼロショット評価ではQwen2.5-VLが構造化出力生成とエンティティ抽出に強い能力を示し、ChatGPT-4oは最高性能だがフォールバックテキストを頻繁に返す結果となった。これは小規模オープンウェイトモデルの潜在的可能性を示している。
5. 結論
本研究では、全ページ文書からのエンドツーエンド情報抽出を評価するための新しいデータセットとベンチマークを提示しました。我々の実験では、従来の全ページ抽出モデルを2つのオープンウェイトLVLMと比較しました。結果は従来のモデルが、はるかに小さいサイズにもかかわらず、十分なトレーニングデータが利用可能な場合にLVLMを上回ることを示しています。しかし、このシナリオは実用的なアプリケーションではあまり考えられません。訓練に使用できるアノテーション付きサンプルが少ない場合、LVLMは集中的な事前訓練から大きな恩恵を受け、実行可能な代替手段を提供します。さらに、我々の結果は、少数ショット学習者として成功しているにもかかわらず、手書きを含む歴史的コレクションにはゼロショットパフォーマンスがまだ不十分であることを示しています。これはChatGPT4oのような商用モデルでも同様です。