目次
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction
この論文は、デスクトップ環境における視覚的知覚とインタラクションのための初の包括的なオフラインベンチマーク「UI-Vision」を提案し、タスク自動化のためのエージェントの性能評価を行ったものです。
UI-Visionは、オフライン環境におけるデスクトップタスクの自動化を評価するために、83のソフトウェアアプリケーションにおける詳細なアノテーションと明確なメトリクスを提供する、初の包括的なライセンス許可されたベンチマークです。
論文:https://arxiv.org/abs/2503.15661
リポジトリ:https://uivision.github.io/

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
本論文では、文書編集やファイル管理などのタスクを自動化するためにグラフィカルユーザーインターフェイス(GUI)をナビゲートする自律エージェントの重要性を強調しています。既存の研究はオンライン環境に焦点を当てていますが、多くの専門的および日常的なタスクにとって重要なデスクトップ環境は、データ収集の課題やライセンスの問題から十分に探求されていません。
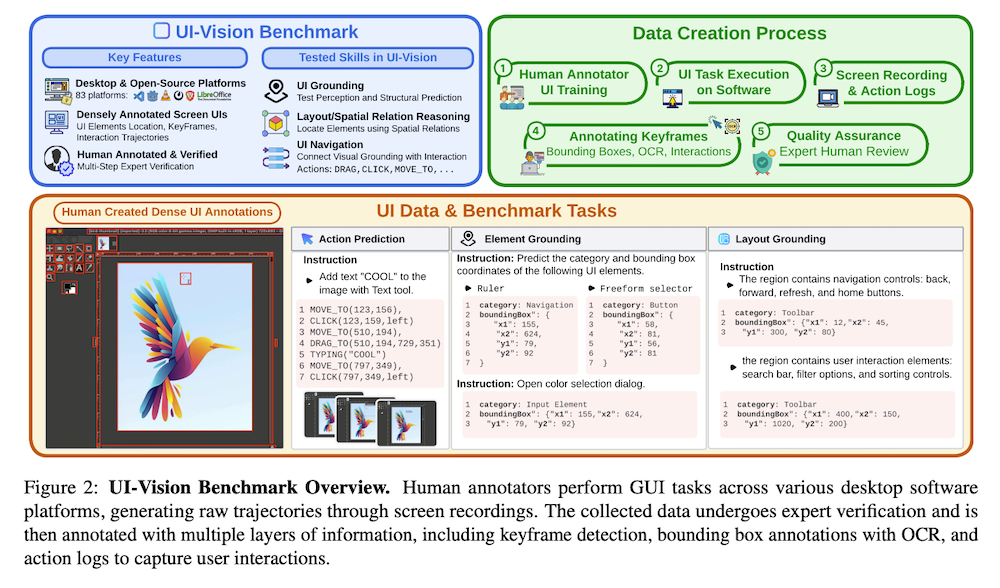
そこで、私たちはUI-Visionを紹介します。これはリアルなデスクトップ環境におけるコンピュータ使用エージェントのオフラインでの詳細な評価のための初の包括的かつライセンス許可されたベンチマークです。UI-Visionは、オンラインベンチマークとは異なり、83のソフトウェアアプリケーションにわたる人間のデモンストレーションの密な高品質アノテーション(バウンディングボックス、UIラベル、アクションの軌跡やクリック、ドラッグ、キーボード入力を含む)や、エレメントグラウンディング、レイアウトグラウンディング、アクション予測という3つの詳細から粗いタスクを提供し、デスクトップ環境におけるエージェントの性能を厳密に評価するための明確なメトリクスを定義しています。
評価の結果、UI-TARS-72Bなどの最先端モデルには、専門的なソフトウェアの理解、空間的推論、ドラッグアンドドロップのような複雑なアクションに関する問題という重要な制限があることが明らかになりました。これらの発見は、完全自律型コンピュータ使用エージェントの開発における課題を浮き彫りにしています。私たちはUI-Visionをオープンソースとして公開することで、リアルなデスクトップタスクのためのより能力の高いエージェントの開発を促進することを目指しています。
1. はじめに
グラフィカルユーザーインターフェース(GUI)は、コマンドラインインターフェースに代わり、デスクトップ、Webブラウジング、モバイルデバイスにおける主要な相互作用方法となっています。大規模言語モデル(LLM)の進歩により、自然言語指示に基づいて推論し動作できるインテリジェントなGUIエージェントの開発が進んでいます。しかし、テキストのみに依存するLLMはGUI自動化に苦戦しており、視覚的レイアウト、空間的関係、非テキストUI要素を解釈する能力が欠けています。マルチモーダルLLMはこの領域で効果を示していますが、デスクトップ環境向けの標準化されたベンチマークの欠如が進展を妨げています。現在のベンチマークは主にWebやモバイル環境に焦点を当てており、デスクトップGUIの評価が困難です。
2. 関連研究
2.1 GUIエージェント
GUIナビゲーションの研究は、MiniWoB++のようなWeb環境から始まり、LLMの登場によって複雑なワークフローを自律的に実行する能力が著しく向上しました。現在の方法論は大きく2つに分類されます:
- 純粋言語エージェント:HTML構造、アクセシビリティツリー、OCRから抽出したUIメタデータを使用し、LLMがタスク固有のアクションを生成します。柔軟性がありますが、構造化されたメタデータに依存するため汎用性に欠けます。
- マルチモーダルエージェント:画像とテキスト記述を組み合わせたマルチモーダルデータセットを使用し、ピクセルレベルの要素認識とコンテキスト対応のインターフェースナビゲーションを可能にします。しかし、デスクトップ環境での実世界UIインタラクション向けの大規模視覚データと標準化されたベンチマークの不足が進展を制限しています。
2.2 GUIベンチマーク
既存のベンチマークはGUIエージェント能力の異なる側面を評価していますが、焦点が断片化しています。Element GroundingベンチマークはアイコンやテキストなどのUI要素を特定する能力を評価し、Action Predictionデータセットはスクリーンショットと履歴に基づくタスク理解と次ステップ推論を評価します。しかし、Layout Groundingは見過ごされがちで、現在の座標ベースの手法ではGUIタスクの構造的関係を捉えられません。ほとんどのベンチマークは特定の分野に特化しており、GUIベンチマークはWeb向けやモバイル向けに偏っています。デスクトップ環境はプロフェッショナルワークフローに重要であるにもかかわらず、十分に探索されていません。
3. UI-Vision
3.1 データ収集
UI-Visionは、83のデスクトップアプリケーションにわたるGUIナビゲーションと視覚的基盤付けのための大規模ベンチマークです。データ収集は以下のステップを含みます:
- デスクトップアプリケーションの選択:Productivity、Development、Creativity、Education、Browsers、Social Media/Entertainmentという6つのドメインにわたる83のオープンソースプラットフォームを厳選しました。
- コンピュータ使用タスクの設計:基本タスク(フォルダの名前変更など)から複雑な操作(ビデオに字幕を適用するなど)まで、実世界のワークフローに基づいたタスクを設計しました。各プラットフォームには5~7個のコンピュータ使用タスクが含まれています。
- ユーザーインタラクションのキャプチャと注釈付け:専門アノテーターが(i)タスクビデオ、(ii)ログ付きアクション(10種類の事前定義されたタイプ)、(iii)キーフレームスクリーンショットをキャプチャしながらコンピュータ使用タスクを実行しました。さらに、キーフレームの全インターフェース要素にバウンディングボックスとラベルで注釈を付けました。
最終データセットは83アプリケーションにわたる450の高品質デモンストレーションで構成されており、各キーフレームには平均71個のラベル付きバウンディングボックスが含まれています。
3.2 UI-Visionベンチマーク
前節で収集した豊富な注釈に基づき、3つの重要なタスクに焦点を当てます:
- ELEMENT GROUNDING:テキストクエリからスクリーンショット内のUI要素のバウンディングボックスを予測するタスク。基本、機能的、空間的という3つのサブタスクがあります。基本設定では、「Actions」のような最小限のテキスト記述からUI要素の位置を予測します。機能的設定では、直接ラベルではなく機能に基づいてUI要素を識別します。空間的設定では、隣接する要素との空間的関係に基づいてUI要素を特定します。
- LAYOUT GROUNDING:UIレイアウトを理解し、機能的・意味的グループにUI要素をクラスタリングし、それらを囲むバウンディングボックスを予測するタスク。このタスクでは、77のプラットフォームにわたる311の人間検証済みクエリ-ラベルペアで構成されたデータセットを使用します。
- ACTION PREDICTION:タスクを達成するための構造化された相互作用シーケンスを通じて、コンピュータ使用タスクを解決するエージェントの能力を評価するタスク。クリック、移動、ドラッグ、タイピング、ホットキーという5つの標準化されたアクションカテゴリに基づいています。442のタスク全体で3191のアクション注釈ペアが含まれています。
4. 実験
4.1 ベースライン
オープンソースVLM(Qwen2-VL-7Bなど)、オープンソースGUIエージェント(CogAgent-9Bなど)、クローズドソースモデル(GPT-4oなど)を含む複数のモデルをテストしました。各モデルは推奨されたプロンプト形式を使用しました。
4.2 評価指標
Element Grounding:予測された点(xi, yi)が正解バウンディングボックス内に入っている場合、予測は正確とみなします。
Layout Grounding:IoU(Intersection over Union)、精度、再現率を使用して予測バウンディングボックスを評価します。
Action Prediction:
- クリック&移動:Dist.(正規化されたユークリッド距離)とRecall@d(ポイントが地上真理から一定距離内にある場合正確とみなす)
- ドラッグ:Dist.(予測と実際の開始・終了座標間の平均変位誤差)とRecall@d
- タイピング&ホットキー:正確性
全体のパフォーマンス測定にはStep Success Rate(予測されたアクションとそのメタデータが正確である場合に成功とみなす)を使用します。
4.3 結果
Element Groundingのパフォーマンス:最高のクローズドソースモデルでも8.7%の精度にとどまり、最高のオープンソースGUIエージェントでも25.5%の精度にとどまりました。機能的基盤付けはGUIエージェントでは基本的基盤付けと同様のスコアですが、空間的基盤付けはすべてのモデルにとって最大の課題です。大きなUI要素や少ない要素を持つスクリーンショットでは精度が向上します。
Layout Groundingのパフォーマンス:VLM(オープンソース・クローズドソース共に)がGUIエージェントよりもUIレイアウト検出において優れています。これは一般的な視覚理解と意味的理解の強さによるものと考えられます。
Action Predictionのパフォーマンス:Gemini-1.5-Proがクリックとドラッグアクションで他のクローズドソースモデルを上回り、オープンソースGUIエージェントUI-TARSが全体で最高のパフォーマンスを示しました。しかし、すべてのモデルがクリックとドラッグアクションに苦戦しており、これはElement Groundingタスクで観察された不十分な基盤付けを反映しています。
5. 結論
UI-Visionは、83のデスクトップアプリケーションをカバーする大規模GUIベンチマークであり、最も広範で多様なデータセットの一つです。(i) Element Grounding(テキストクエリに基づいてUI要素を特定・位置特定する能力を測定)、(ii) Layout Grounding(UI要素を機能的グループにクラスタリングし、それらを囲むバウンディングボックスを定義する能力を評価)、(iii) Action Prediction(タスク完了に必要な正確なアクションを予測する能力をテスト)という3つの構造化された評価タスクを構築しました。最先端VLMを用いた実験では、UI要素の基盤付けとアクションの正確な予測における困難さなど、重要なギャップが明らかになりました。デスクトップにおけるUIインタラクションモデリングのさらなる研究が必要です。