目次
Marmot: Multi-Agent Reasoning for Multi-Object Self-Correcting in Improving Image-Text Alignment
この論文は、画像とテキストの整合性を向上させるために、複数のエージェントによる自己修正を用いた新しいフレームワーク「Marmot」を提案しています。
Marmotフレームワークは、マルチエージェントシステムを活用して複雑なマルチオブジェクトシーンにおける干渉を効果的に軽減し、画像生成におけるオブジェクトのカウントや属性割当の精度を大幅に向上させる点が特徴です。
論文:https://arxiv.org/abs/2504.20054

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
本論文では、Marmotと呼ばれる新たなフレームワークを提案します。これは、マルチエージェント推論を用いたマルチオブジェクト自己修正の手法で、画像とテキストのアラインメントを向上させ、より一貫したマルチオブジェクトの画像編集を促進します。
このフレームワークは、自己修正タスクをカウント、属性、空間関係の三つの重要な次元に分解し、さらにオブジェクトレベルのサブタスクに細分化する分割統治戦略を採用しています。私たちは、意思決定・実行・検証メカニズムを備えたマルチエージェント編集システムを構築し、オブジェクト間の干渉を効果的に軽減し、編集の信頼性を向上させます。
サブタスクの統合問題を解決するために、マスク誘導の二段階潜在空間最適化を用いたピクセルドメインスティッチングスムーザーを提案します。この革新により、サブタスク結果の並列処理が可能となり、ランタイム効率が向上し、マルチステージの歪み蓄積を排除します。広範な実験により、Marmotが画像生成タスクにおけるオブジェクトのカウント、属性割当、空間関係の精度を大幅に向上させることが示されました。
1. 導入
拡散ベースの生成モデルは高品質画像生成に優れていますが、複数オブジェクトを含む複雑なシーンでは、数のカウント、属性バインディング、空間的関係に課題があります。近年の研究ではレイアウト制御やMLLMを活用したフレームワークが提案されていますが、単一エージェントに依存し、MLLM能力に左右されます。Marmotは「分割統治」と「問題分解」に着想を得た、マルチエージェント推論による普遍的自己修正フレームワークです。
2. 関連研究
2.1. テキストから画像への生成
拡散モデルを使用したT2I生成は急速に発展しており、DALL-E、Imagen、LDM、SDXLなどのモデルが大規模訓練やアーキテクチャ改良で高品質な画像合成を実現しています。しかし、属性の一貫性に課題があり、本フレームワークはオブジェクト-属性マッチングとカウンティングを強化して対処しています。
2.2. LLMを用いた画像生成と編集
LLMにより画像生成は前例のないレベルに発展し、多くの研究がレイアウト計画、テキストプロンプト最適化、自己修正プロセスにLLMを活用しています。Marmotの革新点は:(1)モジュラーなオブジェクト中心分解、(2)情報干渉を排除する意思決定-実行-検証メカニズム、(3)サブタスク出力を統合し並列実行を可能にするPixel-Domain Stitching Smootherです。
3. 方法
3.1. キャプションとレイアウトの抽出
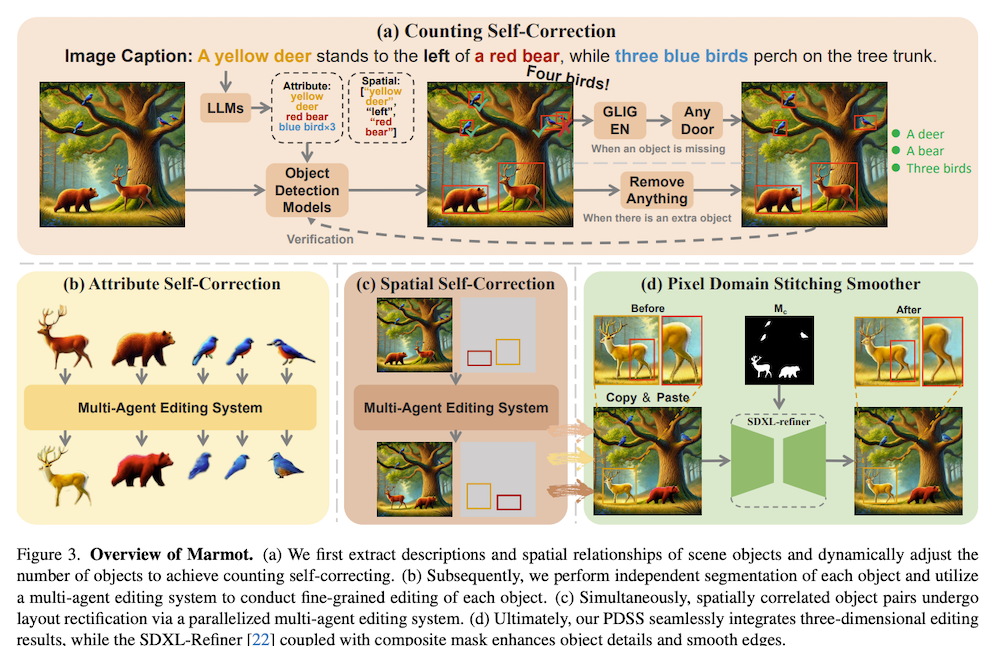
オブジェクトレベルの自己修正は、画像内の各オブジェクトのキャプションとレイアウト抽出から始まります。LLMをパーサーとして使用し、オブジェクト、属性、空間関係を抽出し、オブジェクト検出モデルでバウンディングボックスを生成します。余分なオブジェクトはSAMとLAMAで削除し、不足オブジェクトはGLIGENとAnyDoorで生成します。検証メカニズムにより、すべてのオブジェクトがユーザーの説明と一致するまで確認します。
3.2. オブジェクトレベルのマルチエージェント編集システム
Marmotは一度に1つのオブジェクトまたは2つのオブジェクト間関係に焦点を当て、複雑さを軽減します。システムは3つの役割で構成されています:
- 意思決定者:2段階視覚推論パラダイムで属性不一致や空間関係エラーを検出
- 実行者:InstructPix2PixやUltraEditなどの編集モデルを活用して画像編集を実行
- 検証者:編集結果がユーザー要件を満たしているか評価し、必要に応じて再編集を要求
3.3. Pixel Domain Stitching Smoother
PDSSは背景ぼかしや歪み、連続編集の効率問題に対処します。LAMAでターゲット領域を消去後、サブタスク編集結果を直接貼り付け、SDXL-Refinerで2段階最適化を行います。最初のK回の反復では複合マスクでオブジェクト詳細とエッジ一貫性を強化し、残りの反復で全体的一貫性を確保します。並列処理により効率を向上させながら、背景整合性を維持します。
3.4. 統合テキストから画像およびレイアウトから画像の生成
Marmotはレイアウトから画像生成にも転用可能です。ユーザーがバウンディングボックスとオブジェクト情報を提供する場合、属性自己修正とPDSSモジュールのみを有効化することで、効果的に適応できます。
4. 実験
4.1. 実装の詳細
Marmotは様々なモデルに対応する普遍的プラットフォームとして設計されています。意思決定者と検証者にはLLaMA3-LLaVA-NeXT-8BとLLaMA-3.1-8Bを採用し、実行者には属性編集用UltraEditと空間的自己修正用LLaMA-3.1-8Bを使用しています。
4.2. ベンチマーク
T2I-CompBenchベンチマークを使用し、複雑なマルチオブジェクトシーンにおける構成的推論能力を評価しています。レイアウトから画像生成タスクでは、100のレイアウトに対して色や質感の属性を割り当てています。
4.3. ベースライン
トレーニングフリーの汎用フレームワークとして、T2I-CompBenchとCOCOにおける統合前後のメトリクスを比較しています。LMD、SDXL、PixArt-α、DALL-E 3などのT2Iモデルや、MIGCとInstanceDiffusionのレイアウトから画像モデルにMarmotを適用し、SLDやGenArtistとも比較しています。
4.4. 評価メトリクス
T2I-CompBenchの6つのサブカテゴリに対して、B-VQA(属性バインディング)、UniDetベースメトリクス(空間関係)、CLIPScore(非空間関係)、3-in-1メトリクス(全体評価)を使用しています。また、RTX 3090 GPU上での処理時間測定やInstanceDiffusionとSAMを用いた属性評価など、実用性も評価しています。
4.5. 定性的評価
Marmotは既存モデルの課題(誤った色や位置生成など)を正確に識別・修正し、ユーザーの説明に一致する画像を生成します。マルチエージェントアプローチにより、シーン内の各オブジェクトに均等に注目でき、単一エージェント方式(SLDやGenArtist)では困難な複数オブジェクトの同時処理が可能になります。
4.6. 定量的評価
8BパラメータのLLMとMLLMを活用したMarmotは、色関連タスクでGenArtistとSLDを大幅に上回り、他のタスクでも同等以上のパフォーマンスを示しています。SDXLでは色、形状、テクスチャタスクでそれぞれ11.76%、6.86%、5.47%改善し、空間関係タスクではSDXLとDALL-E 3をそれぞれ13.12%と8.08%向上させています。
4.7. アブレーション研究
- 意思決定-実行-検証メカニズム:検証プロセスにより、色、形状、テクスチャの属性バインディングがそれぞれ5.10%、4.93%、5.19%向上
- 2段階視覚的推論:このメカニズムを除去すると、色、形状、テクスチャタスクがそれぞれ4.37%、1.06%、0.72%低下
- PDSS:並列編集により、連続編集と比較して処理時間が115.31秒から86.47秒へと約25%短縮
4.8. エラーケース分析
主なエラー原因は編集ツールの限界で、複雑なエッジ領域の正確なセグメンテーション困難や編集能力の限界などがあります。しかし、検証メカニズムによる複数シード試行でこれらの問題を軽減できます。
5. 結論
Marmotは分割統治戦略を用いて自己修正タスクを分解し、意思決定-実行-検証メカニズムとPixel-Domain Stitching Smootherにより性能を向上させます。8BパラメータMLLMとLLMのみで、GPT-4ベースのフレームワークを上回る画像-テキスト整合性改善を達成し、様々なモデルに対応できる汎用性と有効性を示しています。