目次
DIVE: Inverting Conditional Diffusion Models for Discriminative Tasks
この論文は、事前に訓練された拡散モデルを利用して、分類タスクからより複雑な物体検出タスクへの応用を探求し、効率的な最適化手法を提案しています。
本論文は、事前学習済みの拡散モデルを「反転」させることで、物体検出タスクの性能を向上させる新しいアプローチを提案し、従来の手法に比べて処理速度の大幅な向上を実現しています。
論文:https://arxiv.org/abs/2504.17253
リポジトリ:https://github.com/LiYinqi/DIVE

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
拡散モデルは、画像や動画生成などのさまざまな生成タスクにおいて著しい進展を示しています。本論文では、事前に学習された拡散モデルを利用して識別タスクを実行する問題を検討します。
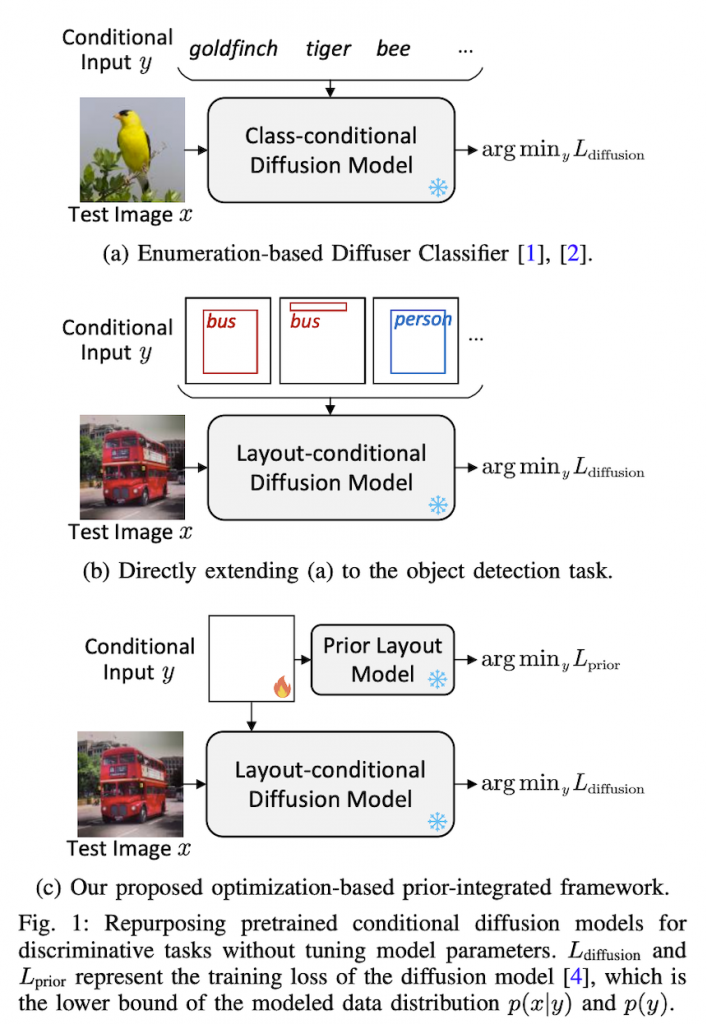
具体的には、事前に学習された固定の生成拡散モデルの識別能力を分類タスクからより複雑な物体検出タスクに拡張するために、事前に学習されたレイアウトから画像への拡散モデルを「反転」させます。この目的のために、重い予測列挙プロセスを置き換えるための勾配に基づく離散最適化アプローチと、ベイズの法則をより正確に利用するための事前分布モデルをそれぞれ提案します。
実証結果は、本手法がCOCOデータセット上の基本的な識別物体検出ベースラインと同等であることを示しています。さらに、本手法は、精度を犠牲にすることなく、以前の拡散ベースの分類手法を大幅に加速することができます。
DIVE: 識別タスクのための条件付き拡散モデルの反転
1. 序論
拡散モデルは画像・動画生成などの生成タスクで顕著な進歩を遂げています。本論文では、事前学習済み拡散モデルを識別タスクに活用する問題を研究しています。具体的には、事前学習済みのレイアウトから画像への拡散モデルを「反転」することで、事前学習済み生成拡散モデルの識別能力を分類タスクから、より複雑な物体検出タスクへと拡張します。そのために、重い予測列挙プロセスを置き換えるための勾配ベースの離散最適化アプローチと、ベイズの法則をより正確に利用するための事前分布モデルを提案しています。
2. 関連研究
2.1 拡散モデル
拡散モデルは、データに徐々にノイズを加えるフォワードプロセスを定義し、このプロセスを反転して新しいデータを生成するマルコフ連鎖を通じてデータ分布を近似する生成モデルです。これらのモデルは、高忠実度のコンテンツ合成能力により、画像生成、画像編集、動画生成などの様々な生成タスクで注目を集めています。
2.2 識別タスクのための生成モデル
生成モデルを識別タスクに活用する代表的なアプローチには以下があります:
- 識別モデルを訓練するための画像生成
- 事前学習済み生成モデルからの特徴抽出と学習可能な識別ヘッドの追加
- アーキテクチャ修正と追加訓練による条件付き画像から特徴の生成
- セグメンテーション関連タスクのためのアテンションマップの活用
最近の方法ではベイズの法則を用いて画像生成拡散モデルを識別タスクに直接変換しています。本研究では、この手法をさらに複雑な物体検出タスクに拡張します。
2.3 生成モデルの反転
生成モデルの反転は通常、与えられた画像の初期ノイズ表現を見つけることを指し、生成モデルを使用してその画像を再構成するために使用されます。GANの場合、最適化ベースのアプローチやエンコーダベースのアプローチ、あるいはその組み合わせが使用されます。拡散モデルでは、DDIMで提案された一般化された決定論的フォワード拡散プロセスを通じて反転が行われます。
3. 方法
3.1 条件付き拡散モデルの基礎
拡散モデルは、クリーン画像にノイズを段階的に追加するフォワードプロセスを逆転させるように訓練される尤度ベースの生成モデルです。条件分岐は、制御可能な画像合成を可能にするために入力yをデノイジングネットワークにエンコードします。クラスラベルのエンコーディングは、整数クラスインデックスを埋め込みベクトルにマッピングする学習可能な埋め込み層を使用して実装できます。
3.2 識別タスクのための条件付き拡散モデルの反転
事前学習済み条件付き拡散モデルpθ(x|y)を用いて、ベイズの法則により識別タスクを実行します:arg max_y pθ(y|x) = arg max_y pθ(x|y)p(y)。理論的な問題として、条件付き拡散モデルは事前分布p(y)を考慮せずに条件付き尤度pθ(x|y)のみをキャプチャします。
3.2.1 事前モデリング
ラベルの事前分布をモデル化するために、拡散モデルpφ(y)を構築します。これは、ラベル空間内で動作するラベル生成モデルです。物体検出の場合、入力はノイズが加えられたレイアウト埋め込みのシーケンスで、モデルは追加されたノイズシーケンスを予測するように訓練されます。
3.2.2 最適化ベースの拡散モデル反転
可能なすべての予測を試すのではなく、予測yを最適化して事後確率目標を最大化することを提案します。具体的には、学習可能なパラメータvを埋め込み空間に設置し、離散出力空間に制限して、勾配法を使用して最適化します。この離散最適化トリックは勾配が学習可能なパラメータに流れるようにします。
3.2.3 実装
各ステップでノイズとタイムステップをサンプリングし、設定された最適化ステップ数でvを更新します。事前に保存された固定ノイズとタイムステップのセットを使用して、最適化プロセス中に損失値を定期的に評価します。学習可能な埋め込みを凍結された語彙の[none]埋め込みで初期化することが効果的です。
4. 実験
4.1 物体検出のためのDIVE
4.1.1 セットアップ
COCO 2017データセットを使用して実験を行い、500画像のサブセットでDIVEを評価しました。LDMの公式コードを使用してレイアウトから画像への拡散モデルを再訓練し、トランスフォーマーをレイアウトエンコーダとして採用しました。事前レイアウト拡散モデルはレイアウトから画像へのモデルのレイアウトエンコーダと同様のアーキテクチャを共有しています。
4.1.2 識別検出器との比較
DIVEを他の拡散モデルベースの方法や純粋な識別方法と比較しました。DIVEは同じ事前学習済み拡散モデルを使用する他の生成-識別ハイブリッド方法よりも優れており、基本的な識別検出器であるFaster R-CNNと競合する結果を達成しました。興味深い現象として、DIVEはAP50では劣るものの、AP75では優れており、全体的なAPでわずかに勝利しています。
4.1.3 アブレーション研究
提案されたコンポーネントの影響を研究しました。事前モデルと語彙内最適化の両方が全体的なパフォーマンスに重要であることがわかりました。事前モデルがなければ、反転されたシーケンス(予測)には多くの冗長オブジェクトと不正な境界ボックスが含まれます。語彙内離散最適化なしでは、最適化プロセスは与えられた画像の内容を再構築することのみに焦点を当てます。
4.2 画像分類のためのDIVE
最適化ベースの方法と以前の列挙ベースの方法であるDiffusion Classifierを画像分類タスクで精度と速度の点で比較しました。ImageNet-1kで事前学習されたDiffusion Transformer(DiT)を条件付き拡散モデルとして反転しました。DIVEはDiffusion Classifierとほぼ同じ精度を達成しながら、〜14倍の高速化を実現しました。
4.3 条件付き拡散モデル評価のためのDIVE
DIVEを使用して、識別能力の観点から異なる条件付き拡散モデルを評価しました。クラス条件付きモデルでは、DiT-XL/2とLDM-4を比較し、レイアウト条件付きモデルでは、セクション4.1で使用したモデル(LDM-8)と別の小さいLDM(LDM-8-S)を比較しました。DIVEからの識別メトリクスはFIDなどの他のメトリクスと一致しており、モデルの一般的な品質を反映しています。
5. 結論
本論文では、ベイズの法則のもとで識別ラベルを生成するために条件付き拡散モデルを反転させる最適化ベースのアプローチを提案しました。経験的に、提案された最適化ベースのアプローチは画像分類タスクで以前の列挙ベースの方法よりもはるかに高速であり、より複雑な物体検出タスクを純粋に事前学習済み生成モデルで実行することを可能にします。将来の研究では、提案された最適化ベースのアプローチをさらに加速したり、セマンティックセグメンテーションなどのより複雑な密度タスクに拡張したりすることが考えられます。