目次
Towards Leveraging Large Language Model Summaries for Topic Modeling in Source Code
この論文は、大規模言語モデル(LLM)の要約を利用してPythonコードのトピックモデリングを行い、コードの構造を意味的に豊かに表現する新しい手法を提案しています。
この論文の特徴は、大規模言語モデルによる要約を用いて、ソースコード内の意味のあるトピックを抽出する新しい手法を提案しており、従来の手法が依存していた自然言語要素が欠如していても効果的にトピックモデリングを行える点です。
論文:https://arxiv.org/abs/2504.17426
リポジトリ:https://zenodo.org/records/15036066

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
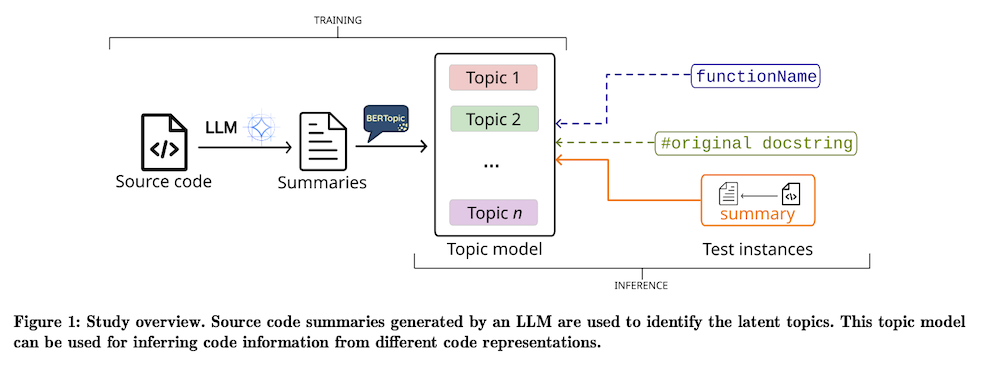
概要
ソースコードの理解はソフトウェアエンジニアリングコミュニティにおいて非常に興味深いテーマであり、プログラマーがソフトウェアの保守や再利用などのさまざまなタスクを行うのに役立ちます。最近の大規模言語モデル(LLM)の進展は、プログラム理解能力において驚くべき成果を示しており、トランスフォーマーベースのトピックモデリング技術はテキストから意味情報を抽出する効果的な方法を提供します。
本論文では、これらの強みを組み合わせて、Pythonプログラムのコーパス内の意味のあるトピックを自動的に特定する新しいアプローチを提案し、探求します。我々の方法は、LLMにコードを要約させて得られた説明にトピックモデリングを適用することから成り立っています。抽出されたトピックの内部的一貫性を評価するために、それらを関数名のみから推測されたトピックや既存のドキュメント文字列から導出されたトピックと比較します。
実験結果は、LLMによって生成された要約を活用することで、コード構造の解釈可能で意味的に豊かな表現が得られることを示唆しています。この有望な結果は、自動ドキュメンテーションやタグ付け、コード検索、大規模リポジトリにおけるソフトウェアの再編成や知識発見など、さまざまなソフトウェアエンジニアリングのタスクにおいて有益に適用できることを示しています。
1. はじめに
1.1 概要
ソースコードの理解はソフトウェア工学において重要な課題であり、プログラマーがコードの保守や再利用等のタスクを行う上で役立つ。本論文では、大規模言語モデル(LLM)の進展を活かし、トピックモデリング技術を用いてPythonプログラムの意味のあるトピックを自動的に特定する新たなアプローチを提案している。具体的には、LLMにコードを要約させ、その要約に基づいてトピックモデリングを行う手法を採用している。
2. 要約に基づくトピックモデリング
2.1 研究の背景
従来のトピックモデリング手法は、識別子やコメントなどの自然な要素に依存しており、この依存が効果を制限する可能性がある。本研究は、これらの自然な要素が取り除かれた場合でも効果的なトピックモデリング技術を定義することを目的としている。
2.2 手法
本研究では次の手順を踏んでいる:
1. コメントとドキュメンテーション文字列を削除し、関数名を難読化したPython関数を用意する。
2. LLMを活用してこれらの関数の要約を生成する。
3. 生成された要約に対してトピックモデリングを適用する。
2.3 トピックモデリングの定義
トピックモデリングでは、各ドキュメントに対してトピック分布を定義し、モデルによって推定されるトピックとの関連性を評価する。モデルは、LLM生成の要約から得られたトピックと、既存のドキュメントストリングから得られたトピックを比較する。
3. 実験設定
我々の実験は、CodeSearchNetからランダムに抽出した10,000のPython関数を対象に実施した。各関数のJSONオブジェクトから、関数名、ソースコード全体、および関数のドキュメント文字列の属性を抽出した。関数名は固定のプレースホルダに置き換え、コメントも完全に削除することで、LLMが純粋にコードの構造やロジックに基づいて要約を生成するようにした。要約生成には、計算効率とパフォーマンスのバランスを考慮してGemma2 2B-itモデルを使用し、BERTopicアルゴリズムでトピックモデリングを行った。
4. 結果
トピックモデリングの結果は、主にCvコヒーレンススコアで評価した。このスコアは、各トピック内の上位単語間の意味的一貫性を測定するものである。我々の手法で生成されたトピックは平均約0.60のコヒーレンススコアを示し、意味のある単語クラスタが形成されていることが確認された。表1に示すように、「HTTP通信」や「ネットワーク通信」「行列演算」など、意味的に明確で分離されたトピックが抽出された。UMAPを用いた二次元空間での可視化では、セマンティックに類似した文書が効果的にグループ化されていることが示された。
5. 議論
我々の手法の価値は、LLMの内部表現を活用して意味的に豊かな自然言語説明を生成し、それに基づいてトピックモデルを構築する点にある。従来のアプローチと比較した場合、我々の手法はコメントや意味のある識別子がないコードに対しても効果的である。表2に示す結果から、LLM生成の要約に基づくトピックは、開発者が作成したドキュメントから得られる参照トピックに近いことが確認された。さらに、関数名だけから推論されるトピックよりも、LLM要約からのトピックの方が参照トピックとの類似性が高いことが示された。
6. 結論と今後の方向性
LLMを活用したこの新たな手法は、文書やコメントが存在しないコードのトピックモデルを構築する際に優れた性能を発揮する。今後は、この手法を他のソースコードの知識抽出タスクに適用する研究が期待される。