目次
AnomalyGen: An Automated Semantic Log Sequence Generation Framework with LLM for Anomaly Detection
この論文は、異常検出のための自動化されたログ生成フレームワーク「AnomalyGen」を提案し、既存のログデータセットの課題を克服するために大規模言語モデル(LLM)を活用した新しいアプローチを示しています。
AnomalyGenは、強化プログラム分析とChain-of-Thought推論を融合させることで、実行なしでの反復的なログ生成と異常アノテーションを可能にし、従来の静的解析ツールに比べて実際のシステムの動的特性をより忠実に反映したログデータを生成します。
論文:https://arxiv.org/pdf/2504.12250

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
ログはソフトウェアシステムの異常検出に不可欠ですが、高品質な公的ログデータセットの不足が、ログベースの異常検出技術の発展を大きく妨げています。既存の公的ログデータセットには、(1)イベントのカバレッジが不完全であること、(2)静的解析に基づく自動生成フレームワークの信頼性が欠如していること、(3)意味的な認識が不十分であることという三つの根本的な制限があります。
これらの課題に対処するため、本論文ではAnomalyGenを提案します。これは異常検出のための初の自動ログ合成フレームワークです。このフレームワークは、強化プログラム分析とChain-of-Thought(CoT)推論を組み合わせた新しい四段階のアーキテクチャを特徴としており、実際のシステム実行を必要とせずに反復的なログ生成と異常アノテーションを可能にします。
HadoopとHDFSの分散システムでの実験評価により、AnomalyGenは既存のデータセットに比べてログイベントカバレッジが大幅に向上し(既存データセットの38倍から95倍の改善)、静的解析ツールと比較してより現実的なログシーケンスを生成することが示されました。AnomalyGen生成データでベンチマークデータセットを増強すると、F1スコアが最大3.7%改善され(最先端の異常検出モデル3つでの平均1.8%の改善)、この研究は自動ログ分析のための高品質なベンチマークリソースを確立し、ソフトウェア工学におけるLLMの応用に新しいパラダイムを切り開きました。
1. 序論
ログはソフトウェアシステムの異常検知に不可欠ですが、高品質な公開ログデータセットの不足が技術開発を妨げています。既存のデータセットには(1)イベントカバレッジの不完全さ、(2)静的分析ベースの自動生成フレームワークの信頼性の低さ、(3)意味認識の不足という根本的な制限があります。これらの課題に対処するため、AnomalyGenは強化されたプログラム分析とChain-of-Thought推論を組み合わせた四段階のアーキテクチャを特徴とし、実際のシステム実行なしでログ生成と異常注釈を可能にします。
2. 動機研究
2.1 研究対象
CCF-A会議の論文分析に基づき、D-HadoopとD-HDFSという広く使用されている分散システムログデータセットを選定しました。これらはベンチマークデータセットであり、その限界は既存のログ生成技術の共通問題を典型的に示しています。
2.2-2.4 既存データセットの限界
既存データセットには重大な問題があります:(1)Hadoopベンチマークは限られたテストプログラムしか含まず、イベントカバレッジに大きなギャップがあります。(2)静的分析ツールはランタイム情報の欠如や反射呼び出しのマッピング困難などの欠陥があります。(3)生成されたログシーケンスは実行コンテキストのセマンティクスを欠いており、ログと制御フローのマッピングが曖昧です。
3. 方法論
3.1 概要
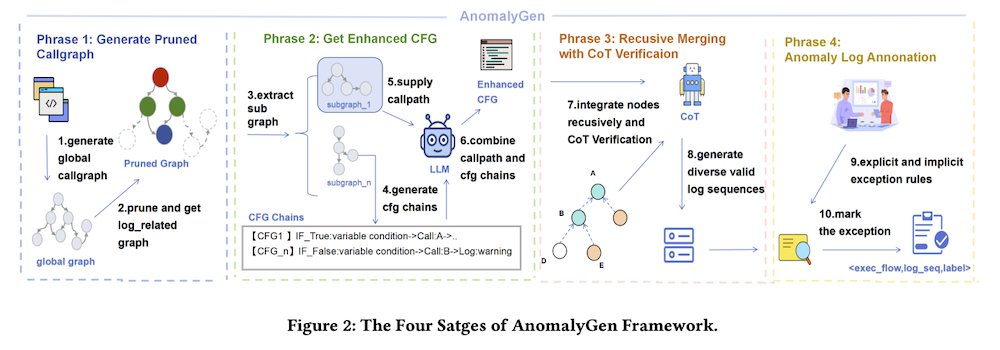
AnomalyGenは四段階の進歩的強化フレームワークを採用しています:静的分析によるログコールサブグラフの構築、詳細なプログラムセマンティック分析、LLM推論検証による再帰的マージ、知識ルールによる異常ラベリングです。
3.2 フェーズI:ログ関連コールグラフのプルーニング
Hadoop 3.3.6ソースコード分析から、295,216メソッドノードのうち1.91%(5,635)がログAPIを直接呼び出していることが判明しました。効率化のため、ログAPIをアンカーポイントとして使用し、コール連鎖を逆方向にたどって徐々にログ関連メソッドをマーキングする二段階プルーニングアプローチを採用しています。
3.3 フェーズII:詳細なサブグラフマイニングと制御フロー図の強化
エントリしきい値と深さしきい値を設定し、グローバルグラフから代表的なサブグラフを抽出します。LLMを使用してノードの三要素情報(ソースコード、コールパス、ログ指向CFG)を変換し、単一ノードの拡張CFGを生成します。
3.4 フェーズIII:CoT推論検証による再帰的ログマージ
スタック構造を使用して、ボトムアップ戦略に従ってサブノードシーケンスを再帰的に統合し、LLMのCoT能力を活用してマージプロセス中のデータフローと制御フローを論理的に検証します。
3.5 フェーズIV:知識駆動の例外ログラベリング
明示的な例外ヒント(”Exception”、”ERROR”など)と暗黙的な信号(エラーコードや失敗キーワードなど)を捕捉するルールを開発し、ドメイン専門家による検証を通じて注釈品質を確保します。
4. 実装
AnomalyGenは主にJavaとPythonで実装されています。グローバルコールグラフ生成にはjava-callgraph2を、包括的なプログラム分析にはjavaparser、解析結果のPythonへの転送にはpy4jを使用しています。広範なコールパスデータ管理にはpython-mysqlを採用し、GPT-4oやDeepSeek-Chatなどの大規模言語モデルをCoT推論に統合しています。
5. 実験
5.1 実験設定
D-HadoopとD-HDFSデータセットを使用し、複数の障害タイプと詳細な異常注釈を含む広く使用されている分散システムログデータセットを対象としました。評価指標としてはログイベント総数、カバレッジ、既存データセットに対する効果などを使用しています。
5.2 RQ1:AnomalyGenデータの包括性
AnomalyGenは全プロジェクトのログイベントの包括性を効果的に向上させ、平均約97.48%のカバレッジを達成しました。従来のデータセットと比較して、生成されたログイベント数は38〜95倍高く(HDFSシナリオでは30から2874イベントに、Hadoopシステムでは242から9225ログに拡大)、既存データセットの大部分をカバーしています。
5.3 RQ2:既存メソッドと比較したリアルさ
AnomalyGenは動的ロギングメソッド解析、制御フロー整合性、動的パラメータシミュレーションの3つの側面で既存ツール(AutoLogなど)と比較し、コード例を通じてその優位性を検証しました。静的分析では解決できない動的呼び出しや例外処理などをLLM強化によって処理できることが示されています。
5.4 RQ3:文脈セマンティック情報の保持
AnomalyGenは全実行プロセスの制御フローを追跡するグラフを生成し、スタッフ実践により、このような制御フロー図の存在がログと対応する制御フローを見つける時間を5倍以上節約できることが明らかになりました。
5.5 RQ4:異常検知問題への利点
Transformer、CNN、LSTMを含む3つの異常検知モデルを、AnomalyGenデータセットありとなしのベースラインデータセットでそれぞれトレーニングし、精度、再現率、F1スコアでパフォーマンスを比較しました。AnomalyGenデータセットで強化されたモデルは平均約1.8%のF1スコア向上を示し(LSTMは0.917から0.954に3.7%向上)、異常検知技術開発に高品質なデータセットを提供できることが実証されました。
6. 有効性への脅威
AnomalyGenは次の主な有効性への脅威に対処しています:(1)動的パラメータ解決の制限(DPRLとして略):AnomalyGenはLLMを通じて動的パラメータを生成しますが、実際のシナリオからの逸脱があり得ます。(2)LLM推論の不確実性:AnomalyGenは制御フロー推論のためにLLMに依存しますが、出力にランダム性や論理エラーがある可能性があります。(3)不完全な異常注釈ルール:フェーズIVの異常注釈は明示的・暗示的ルールに依存していますが、一部の異常シナリオがカバーされない場合があります。
7. 関連研究
7.1 ログステートメント生成
開発者はデバッグやソフトウェア保守を支援するためにログステートメントを記述しますが、十分な高品質で代表的なログの取得は課題です。LANCE、LoGenText、AutoLog、SCLoggerなどの自動ログ生成フレームワークがこの課題に対する解決策を提供しています。
7.2 ログ異常検知
伝統的なログ異常検知研究はグラフ構造やセマンティック分析などの観点から探究されています。LogFormerなどのフレームワークは、異なるドメイン間でのログ異常検知タスクの一般化能力を向上させるために提案されました。
7.3 大規模言語モデルに基づくログ分析
ログは意味情報が豊富な半構造化テキストです。自然言語処理分野での事前学習言語モデルの成功により、多くの研究がログ分析にこれらのモデルを活用しています。
8. 結論
AnomalyGenは包括性、リアリズム、文脈的整合性の利点を持ち、より包括的かつリアルなログデータを効果的に生成することで異常検知モデルのパフォーマンスを大幅に向上させます。異常検知技術開発のための堅固なデータ基盤を提供するベンチマークデータジェネレーターとして使用できます。