目次
SRMT: Shared Memory for Multi-agent Lifelong Pathfinding
この論文は、マルチエージェント環境における協調行動を促進するために、共有再帰的メモリを利用した新しい手法「SRMT」を提案し、その効果を評価したものです。
SRMTは、エージェント間の情報交換を暗黙的に行うことで、協力的な行動調整を可能にし、特にスパース報酬の状況下でのパフォーマンスを大幅に向上させる点が特徴です。
論文:https://arxiv.org/abs/2501.13200
リポジトリ:https://github.com/Aloriosa/srmt
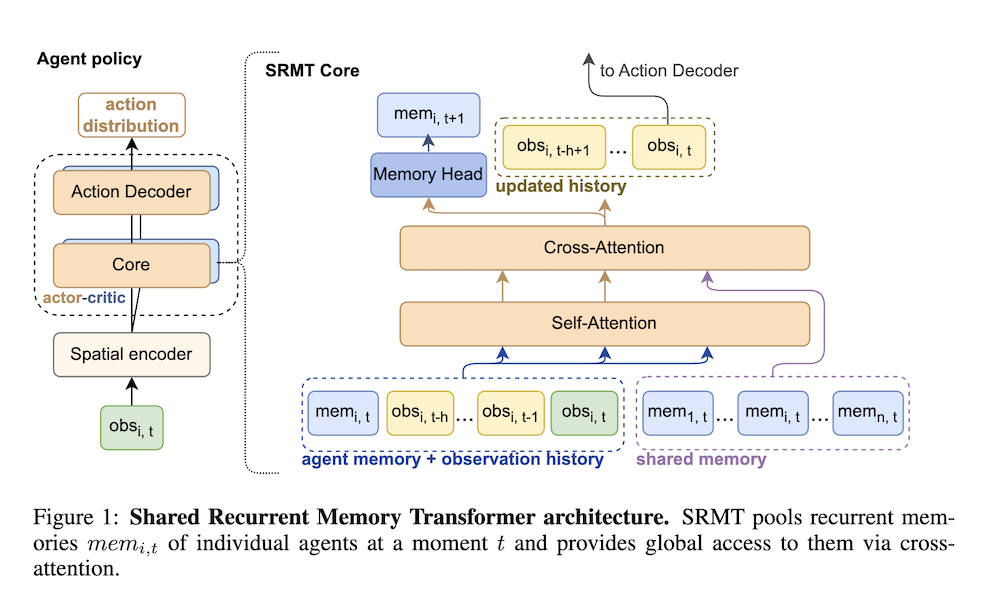
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
マルチエージェント強化学習(MARL)は、さまざまな環境における協力的および競争的なマルチエージェント問題の解決において重要な進展を示しています。MARLの主な課題の一つは、協力を達成するためにエージェントの行動を明示的に予測する必要があることです。この問題を解決するために、我々はShared Recurrent Memory Transformer(SRMT)を提案します。
SRMTは、個々の作業メモリをプールし、グローバルにブロードキャストすることで、エージェントが情報を暗黙的に交換し、行動を調整できるようにすることで、メモリトランスフォーマーをマルチエージェント設定に拡張します。SRMTを部分的に観測可能なマルチエージェント経路探索問題において、狭い通路を通過する必要があるおもちゃのボトルネックナビゲーションタスクとPOGEMAベンチマークタスクセットで評価しました。ボトルネックタスクにおいて、SRMTはさまざまな強化学習のベースラインを一貫して上回り、特にスパース報酬の下で効果を発揮し、トレーニング中に見たよりも長い通路に対しても効果的に一般化します。
POGEMAマップ、すなわち迷路、ランダム、MovingAIを含むタスクにおいて、SRMTは最近のMARL、ハイブリッドおよび計画ベースのアルゴリズムと競争力があります。これらの結果は、トランスフォーマーベースのアーキテクチャに共有再帰メモリを組み込むことで、分散型マルチエージェントシステムにおける調整が強化される可能性を示唆しています。
SRMT: マルチエージェントの生涯経路探索のための共有メモリ
1. 概要
本論文では、マルチエージェント強化学習(MARL)の文脈において、協調的な行動を促進するための新しい手法「共有再帰メモリトランスフォーマー(SRMT)」を提案しています。SRMTは、エージェントの個々の作業メモリをプールし、グローバルにブロードキャストすることで、エージェント間の情報交換と行動調整を実現します。このアプローチは、エージェントの行動を明示的に予測する必要性を軽減し、協力的な問題解決を可能にします。
2. 提案手法
SRMTは、メモリトランスフォーマーをマルチエージェント設定に拡張したもので、各エージェントの作業メモリを集約し、全体に情報を伝達する仕組みを持っています。この再帰的なメモリ構造により、エージェントは過去の経験を考慮に入れつつ未来の行動を計画し、環境内での相互作用を改善します。
3. 実験設定
SRMTの有効性を評価するために、部分観測可能なマルチエージェント経路探索問題について実験を行いました。具体的には、以下の二つのタスクに焦点を当てました:
- ボトルネックナビゲーションタスク:エージェントが狭い廊下を通過する必要がある課題です。
- POGEMAベンチマーク:迷路、ランダムマップ、MovingAIタスクを含む多様なシナリオでの性能評価です。
4. 実験結果
ボトルネックナビゲーションタスクにおいて、SRMTは従来の強化学習アルゴリズムを一貫して上回る性能を示し、特にスパースな報酬条件下でも効果的でした。また、訓練中に見たことのない長い廊下に対しても一般化能力を持つことが確認されました。POGEMAマップでも、SRMTは最近のMARLアルゴリズムやハイブリッド、計画ベースのアルゴリズムと競争力のある結果を示しました。
5. 考察
これらの結果は、トランスフォーマーに基づくアーキテクチャに共有再帰メモリを組み込むことで、分散型マルチエージェントシステムにおける協調行動が向上する可能性を示唆しています。SRMTは、マルチエージェント環境での協調行動を促進する新たなアプローチとして、強化学習の分野における重要な進展を代表しています。