目次
MiniMax-01: Scaling Foundation Models with Lightning Attention
この論文は、長いコンテキストを効率的に処理できる新しい基盤モデル「MiniMax-01」を提案し、従来のモデルを超える性能を示すとともに、効率的な計算と訓練手法を用いて大規模な言語および視覚言語タスクに対応することを目指しています。
MiniMax-01シリーズは、ライトニングアテンション技術を採用し、従来のモデルに比べて20〜32倍の長いコンテキストウィンドウを効率的に処理できる点が特長です。
論文:https://arxiv.org/abs/2501.08313
リポジトリ:https://github.com/MiniMax-AI/MiniMax-01
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
私たちは、MiniMax-01シリーズ、MiniMax-Text-01およびMiniMax-VL-01を紹介します。これらは、最先端のモデルと比較可能であり、長いコンテキストの処理において優れた能力を提供します。核心は、ライトニングアテンションとその効率的なスケーリングにあります。計算能力を最大限に引き出すために、Mixture of Experts(MoE)と統合し、32のエキスパートと合計4560億のパラメータを持つモデルを作成しました。そのうち、各トークンごとに459億がアクティブ化されます。MoEとライトニングアテンションのために、最適化された並行戦略と非常に効率的な計算-通信オーバーラップ技術を開発しました。このアプローチにより、数百億のパラメータを持つモデルのトレーニングと推論を、数百万トークンにわたるコンテキストで効率的に行うことが可能になります。
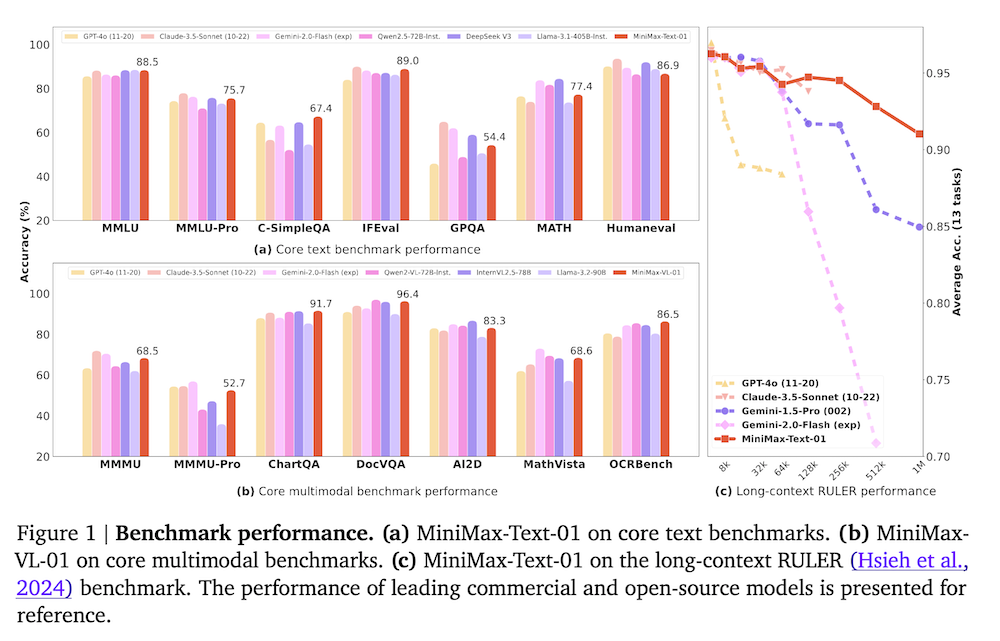
MiniMax-Text-01のコンテキストウィンドウは、トレーニング中に最大100万トークンに達し、推論時には400万トークンに外挿できます。私たちの視覚-言語モデル、MiniMax-VL-01は、5120億の視覚-言語トークンを使って継続的にトレーニングされています。標準的および社内ベンチマークでの実験は、私たちのモデルがGPT-4oやClaude-3.5-Sonnetのような最新のモデルの性能に匹敵しながら、20〜32倍長いコンテキストウィンドウを提供することを示しています。
1. はじめに
1.1 大規模言語モデルとその限界
近年、大規模言語モデル(LLM)および視覚言語モデル(VLM)が急速に進展しており、知識に基づくQ&A、複雑な推論、数学、コーディング、視覚と言語の理解などで優れた性能を発揮している。しかし、現在のモデルの文脈ウィンドウは32Kから256Kトークンに限られ、実用的なニーズには不十分である。この課題を克服するため、本研究は最大で4百万トークンをサポートするモデルの構築を目指している。
1.2 研究の目的と貢献
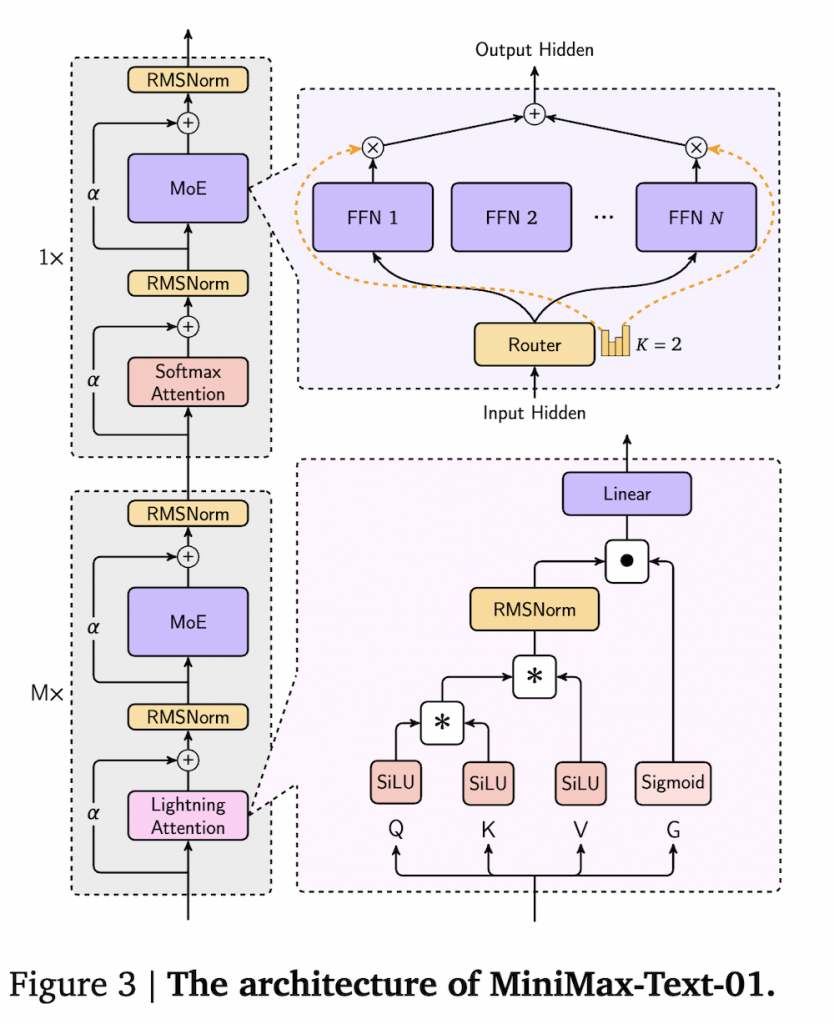
本研究は、MiniMax-Text-01およびMiniMax-VL-01という新しいモデルを紹介し、これらが長文処理能力を実現する方法を探る。特に、Mixture of Experts(MoE)とLightning Attentionを統合したアーキテクチャを採用し、計算効率を高めることで4560億パラメータのモデルを設計した。
2. モデルアーキテクチャ
2.1 Mixture of Experts (MoE)
MoEアプローチを採用し、トークンが複数の専門家にルーティングされることで、スケーラビリティと効率性を向上させる。これにより、特定のタスクに対するパフォーマンスが最適化される。
2.2 線形注意
線形注意は、計算の二次的な複雑さを線形に変換する手法であり、クエリ、キー、バリュー行列を用いて効率的な計算を実現する。
2.3 Lightning Attention
Lightning Attentionは、従来の線形アテンションの最適化された実装で、計算の並列性を最大化することで、効率的な計算を実現する。
3. 計算の最適化
3.1 MoEの最適化
MoEアーキテクチャの最適化では、通信オーバーヘッドを最小化するためにトークンをグループ化し、異なる専門家間での処理を重複させるアプローチを採用した。
3.2 長文最適化
長文トレーニングにおいては、データパッキング技術を用いて計算資源の無駄を最小化する。異なるサンプルを連結することで、計算の冗長性を減らしている。
4. 事前トレーニング
4.1 データ
事前トレーニング用のデータコーパスは、多様なソースから厳選された高品質なデータセットで構成され、厳密なフィルタリングとデデュプリケーション手法が適用されている。
4.2 トレーニング戦略
段階的なトレーニング戦略を採用し、モデルが長大なコンテキストに適応する能力を高める。特に、トレーニングの安定性を向上させるために、コンテキスト長を段階的に拡大するアプローチを取っている。
5. ポストトレーニング
5.1 報酬モデル
モデルの応答を正確性、有用性、無害性に基づいて評価する報酬モデルを構築し、モデルの出力を人間の価値観に合わせたものに調整している。
6. ビジョン言語モデル
6.1 マルチモーダルデータ
MiniMax-VL-01のトレーニングにおいては、画像とテキストのペアを使用し、視覚理解能力を強化するための多段階トレーニング戦略を採用している。
6.2 アーキテクチャ
ViT(Vision Transformer)を使用して視覚エンコーダを構築し、テキストと視覚情報を統合して処理する能力を向上させている。
7. 結論と今後の展望
本研究により、MiniMax-Text-01およびMiniMax-VL-01は優れた性能を持つモデルとして位置づけられ、今後のAGIの発展に貢献することが期待される。さらなる研究を通じて、モデルの改善と新たなアプローチの探求を続けていく意向である。