目次
TableRAG: Million-Token Table Understanding with Language Models
この論文は、言語モデルを用いた表データの理解を向上させるための新しいフレームワーク「TableRAG」を提案し、その効果を評価した研究です。
TableRAGは、クエリ拡張とスキーマ・セル取得を活用することで、全テーブルを入力することなく効率的に必要な情報を取得し、スケーラビリティの問題を解決しながら大規模なテーブル理解の精度を向上させる革新的なフレームワークです。
論文:https://arxiv.org/abs/2410.04739
リポジトリ:https://github.com/google-research/google-research/tree/master/table_rag
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
最近の言語モデル(LM)の進展は、主にテーブルを操作し分析するプログラム支援メカニズムを通じて、表形式のデータに対する推論能力を顕著に向上させました。しかし、これらの手法はしばしば全テーブルを入力として必要とし、位置バイアスやコンテキスト長の制約によりスケーラビリティの課題を引き起こします。
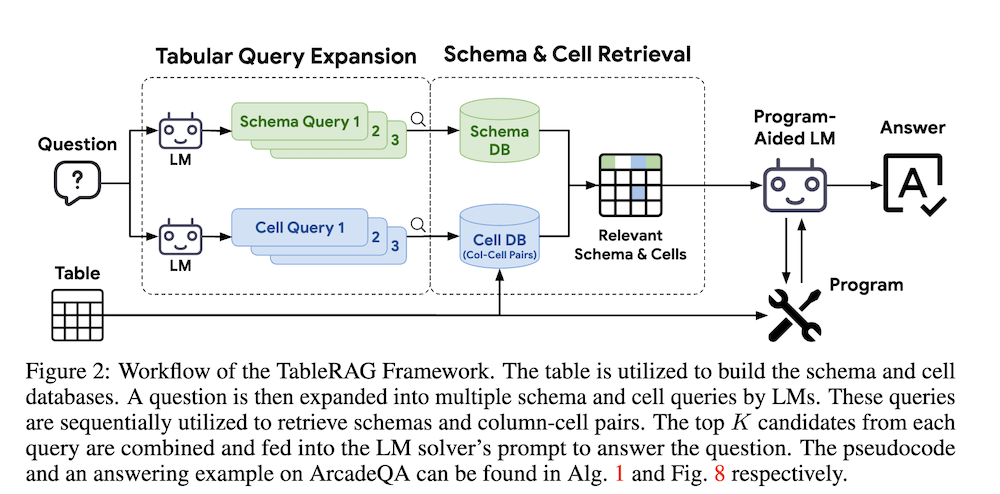
この課題に対応するために、我々はLMベースのテーブル理解のために特別に設計されたRetrieval-Augmented Generation(RAG)フレームワークであるTableRAGを導入します。TableRAGは、重要な情報を特定するためにクエリ拡張とスキーマおよびセルの取得を組み合わせて活用し、それをLMに提供します。これにより、データエンコーディングがより効率的になり、正確な取得が可能となり、プロンプトの長さを大幅に短縮し、情報損失を軽減します。
私たちは、TableRAGの効果をスケールで徹底的に評価するために、ArcadeおよびBIRD-SQLデータセットから2つの新しい百万トークンベンチマークを開発しました。結果は、TableRAGの取得設計が最高の取得品質を達成し、大規模なテーブル理解における新しい最先端のパフォーマンスを実現することを示しています。
TableRAG: ミリオントークンテーブル理解のための言語モデル
1. はじめに
近年、言語モデル(LM)の進展により、テーブルデータの処理能力が向上しましたが、従来の方法は全体のテーブルを入力として必要とし、位置バイアスやコンテキスト長の制約からスケーラビリティに課題があります。本論文では、これらの問題を解決するために「TableRAG」というRetrieval-Augmented Generation(RAG)フレームワークを提案します。
2. 方法論
2.1 TableRAGの設計
TableRAGは、クエリ拡張技術を利用し、スキーマとテーブルのセルの取得を組み合わせて重要な情報を特定します。これにより、データのエンコーディングが効率化され、プロンプトの長さが短縮され、情報の損失が軽減されます。
2.2 実験データセット
評価のために、ArcadeおよびBIRD-SQLデータセットから新たに開発したミリオントークンベンチマークを使用しました。この評価により、TableRAGのスケールでの有効性を徹底的に確認しました。
3. 実験結果
実験の結果、TableRAGは最良の取得品質を達成し、大規模なテーブル理解において新たな最先端性能を示しました。実験の詳細や使用した評価指標については、本文中で述べられています。
4. 結論
TableRAGは、従来の手法の限界を克服し、テーブル理解における新たな基準を確立しました。今後はさらなるデータセットの拡張や、より多様なクエリへの適応能力の向上を目指します。