目次
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
「RetroLLM」は、大規模言語モデルが生成過程で詳細な証拠を直接取得できるようにする統合フレームワークを提案する論文です。
RetroLLMは、リトリーバルと生成を統合したフレームワークにより、外部知識を効果的に活用しつつ、無関係な情報を削減し、証拠生成の精度を向上させる点が特徴です。
論文:https://arxiv.org/abs/2412.11919
リポジトリ:https://github.com/sunnynexus/RetroLLM
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
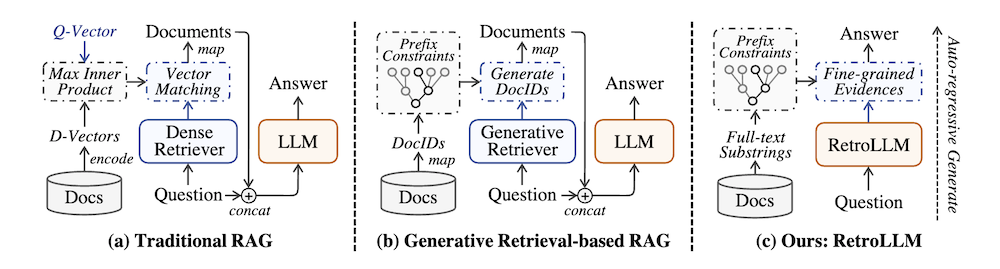
大規模言語モデル(LLM)は驚異的な生成能力を示しますが、しばしば幻覚の影響を受けます。 Retrieval-augmented generation(RAG)は、外部知識を取り入れることで効果的な解決策を提供しますが、既存の方法にはいくつかの制限があります:別々のリトリーバーの追加展開コスト、取得したテキストチャンクからの冗長な入力トークン、リトリーバルと生成の共同最適化の欠如です。
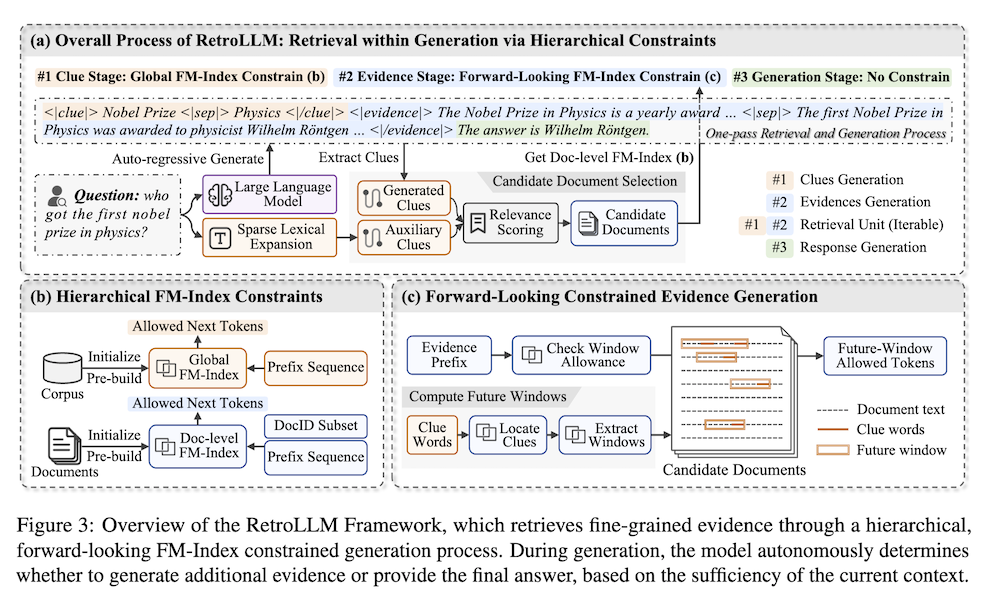
これらの問題に対処するために、私たちはリトリーバルと生成を単一の一貫したプロセスに統合する統一フレームワーク「RetroLLM」を提案し、LLMが制約されたデコーディングを用いてコーパスから直接詳細な証拠を生成できるようにします。さらに、制約された証拠生成の過程での偽の剪定を軽減するために、(1)階層的FM-Index制約を導入し、証拠生成の前に関連文書のサブセットを特定するためのコーパス制約クルーを生成し、無関係なデコーディング空間を減少させ、(2)将来のシーケンスの関連性を考慮する前向き制約デコーディング戦略を導入し、証拠の精度を向上させます。五つのオープンドメインQAデータセットにおける広範な実験は、RetroLLMの優れた性能を示しており、ドメイン内およびドメイン外のタスクの両方で効果的です。
RetroLLMによる大規模言語モデルの強化
1. はじめに
本論文では、RetroLLMという新たなフレームワークが提案されています。大規模言語モデル(LLM)は優れた生成能力を持つ一方で、しばしば誤った情報(ホロウシネーション)を生成するという課題を抱えています。従来の手法である取得強化生成(RAG)は外部知識を取り入れることでこの問題を軽減しようとしていますが、いくつかの制約が残ります。これには、リトリーバーの導入コストや、取得したテキストチャンクからの冗長なトークンの問題、リトリーバルと生成の共同最適化が欠如していることが含まれます。
2. RetroLLMの提案
RetroLLMは、リトリーバルと生成を統合した一貫したプロセスとして設計されています。このフレームワークにより、LLMはコーパスから直接詳細な証拠を生成することが可能になります。主な戦略は以下の通りです。
2.1 階層的FM-Index制約
この手法では、関連する文書のサブセットを特定するために、コーパスの制約を持つ手がかりを生成します。これにより、無関係なデコーディング空間を減少させ、証拠生成の精度を向上させます。
2.2 前向き制約デコーディング戦略
この戦略は、未来のシーケンスの関連性を考慮し、証拠の正確性を向上させることを目指しています。これにより、生成過程における誤ったプルーニングを軽減し、より信頼性の高い情報を提供します。
3. 実験と結果
RetroLLMの性能を評価するために、5つのオープンドメイン質問応答データセットで広範な実験が行われました。結果は、RetroLLMがドメイン内およびドメイン外のタスクにおいて優れた性能を示すことを明らかにしました。
4. 付録と実装
付録では、RetroLLMの実装に関する詳細が記載されており、使用したアルゴリズムや手法が具体的に示されています。これにより、他の研究者がこの手法を再現し、さらなる研究を進めることが可能です。
5. 結論
RetroLLMは、LLMの生成能力を向上させるための効果的な手法を提供しており、情報検索と生成を統合することでホロウシネーションの問題に対処する新たなアプローチを示しています。この手法は、今後の研究や実用的な応用において重要な意義を持つでしょう。