目次
Knowledge Injection via Prompt Distillation
この論文は、新しい知識を大規模言語モデルに効果的に注入するための「プロンプト蒸留」というファインチューニング手法を提案し、従来の手法と比較してその性能を示しています。
本論文の特徴は、自己蒸留アプローチを活用した「プロンプト蒸留」技術により、ファインチューニングによって新しい知識を効果的に学習し、リトリーバル強化生成(RAG)と同等の性能を達成できる点です。
論文:https://arxiv.org/abs/2412.14964
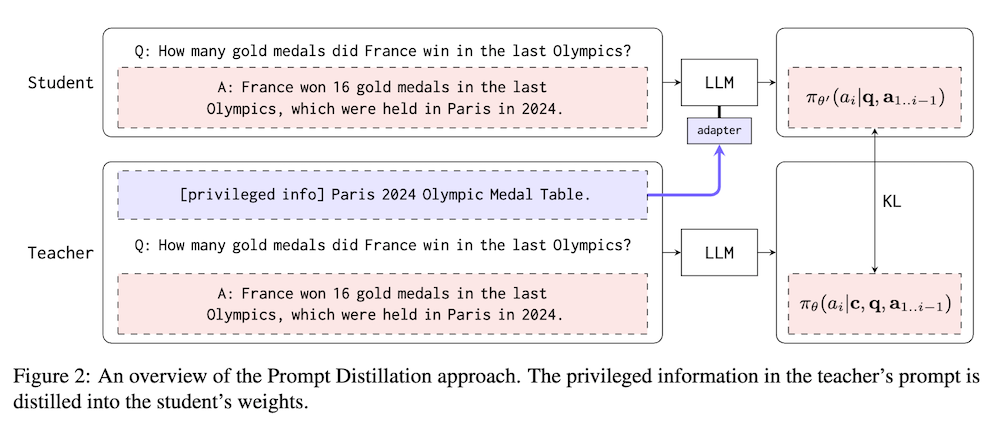
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
多くの実用的なアプリケーションにおいて、大規模言語モデル(LLM)は、事前学習データに存在しない新しい知識を組み込む必要があります。これを行うための主な方法はファインチューニングとリトリーバル強化生成(RAG)です。RAGは知識注入の業界標準として浮上していますが、ファインチューニングはまだ同等の成功を収めていません。
本論文では、新しい知識を学習するためのファインチューニング技術を提案し、これがRAGのパフォーマンスに達することができることを示します。提案された方法は自己蒸留アプローチに基づいており、これをプロンプト蒸留と呼びます。まず、新しい知識に関する質問-回答ペアを生成します。次に、質問-回答ペアを用いて生徒モデルをファインチューニングし、追加の新しい知識をプロンプトに受け取る教師モデルの出力分布を模倣します。生徒モデルは教師モデルと同一ですが、LoRAアダプタが装備されています。このトレーニング手順は、教師のプロンプトから生徒の重みに新しい知識を蒸留することを容易にします。
プロンプト蒸留による知識注入
本論文では、大規模言語モデル(LLM)が事前学習データに存在しない新しい知識を取り入れることの重要性に焦点を当てています。知識注入の方法として、主にファインチューニングとリトリーバル拡張生成(RAG)が挙げられますが、RAGが業界標準として広く用いられているのに対し、ファインチューニングは同等の成功を収めていないと指摘しています。そのため新たに提案されたのが「プロンプト蒸留」という手法です。
方法論
提案されたプロンプト蒸留は、自己蒸留アプローチに基づいています。この手法の主要なプロセスは以下の通りです。
知識の生成
新しい知識に関する質問-回答ペアを生成します。このプロセスは、モデルが新しい情報を理解し習得する基盤を提供します。
学生モデルのファインチューニング:
学生モデルは、教師モデルの出力分布を模倣するように訓練されます。教師モデルは新しい知識をプロンプトに受け取り、その出力を基に学生モデルをファインチューニングします。ここで重要なのは、学生モデルがLoRAアダプターを装備している点です。このトレーニングにより、教師モデルのプロンプトから新しい知識が学生モデルの重みに蒸留されます。
結果と考察
実験結果として、プロンプト蒸留手法はRAGと同等のパフォーマンスを達成することが示されました。この成果により、ファインチューニングの有効性が再評価され、実用的な応用における新しい知識の注入方法としての可能性が強調されています。