目次
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
この論文は、大規模言語モデル(LLM)を評価者として活用する新しいパラダイムについて、定義、分類、評価基準、課題と将来の研究方向性を包括的に調査したものです。
この論文は、LLMを用いた評価手法の新たな枠組みを提案し、従来の方法では捉えきれなかった微妙な判断を可能にすることで、AIとNLP分野における評価の精度を向上させる可能性を示しています。
論文:https://arxiv.org/abs/2411.16594
リポジトリ:https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
この論文は、人工知能(AI)と自然言語処理(NLP)における評価と判断が長年の重要な課題であることを指摘しています。しかし、従来の手法は微妙な特性を判断したり、満足のいく結果を提供したりするには不十分なことが多いです。最近の大規模言語モデル(LLM)の進展は、「LLM-as-a-judge」パラダイムを刺激しており、ここではLLMを活用してさまざまなタスクやアプリケーションにおいてスコアリング、ランキング、選択を行います。
本論文は、LLMに基づく判断と評価の包括的な調査を提供し、この新興分野を進展させるための詳細な概要を示します。まず、入力と出力の両方の視点から詳細な定義を行います。次に、何を判断するか、どのように判断するか、どこで判断するかという三つの次元からLLM-as-a-judgeを探るための包括的な分類法を紹介します。最後に、LLM-as-a-judgeを評価するためのベンチマークをまとめ、主要な課題と有望な方向性を強調し、この有望な研究領域における将来の研究を刺激するための貴重な洞察を提供することを目指します。
以下は、各章ごとに内容をまとめた解説です。
LLMを判定者として活用する新たな研究パラダイム
1. はじめに
本章では、人工知能(AI)および自然言語処理(NLP)における評価と判定の重要性が強調されています。従来の手法(マッチングベースや埋め込みベース)は、微妙な特性を正確に判断するには限界があると指摘されています。近年の大規模言語モデル(LLM)の進展により、「LLMを判定者として活用する」新たなパラダイムが提案され、さまざまなタスクやアプリケーションにおいてスコアリング、ランキング、選択を行うことが可能になっています。
2. LLMの定義と分類
この章では、LLMを用いた判定の詳細な定義が示されています。具体的には、以下の観点から構成されています:
- 入力の観点:LLMに入力されるデータの種類や形式(テキスト、画像、音声など)について詳述。
- 出力の観点:LLMが生成する出力(スコア、ランキング、選択リストなど)の特性を説明。
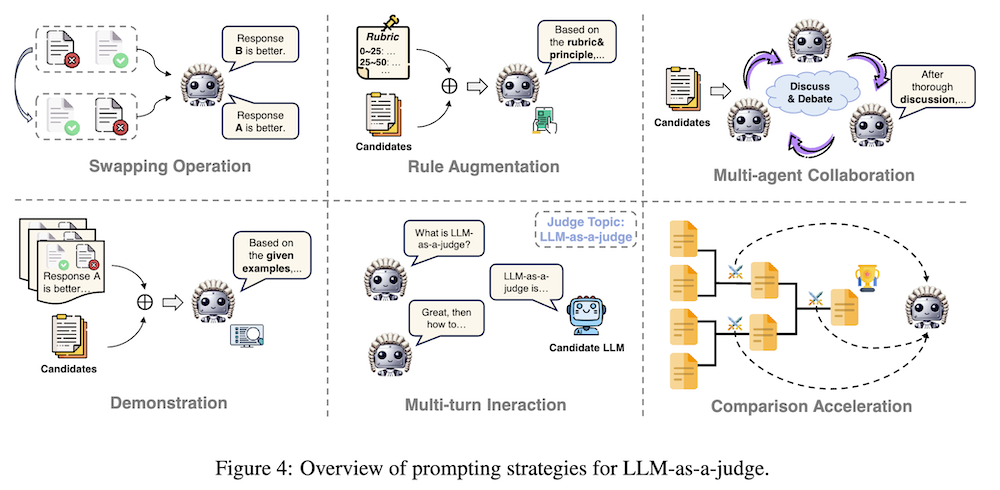
さらに、LLMを判定者として利用するための包括的なタクソノミーが紹介され、「何を判定するか」「どのように判定するか」「どこで判定するか」の三つの次元からアプローチがなされています。
3. 実験と評価基準
この章では、LLM-as-a-judgeの評価に関する実験が詳述されています。具体的には、以下の内容が含まれています:
- ベンチマーク:評価基準を明確にし、LLMの性能を比較するための基準が提供されています。
- 実験設定:使用したデータセット、評価指標、比較対象となる手法などが具体的に説明されています。
実験結果は、LLMの判定精度や適用可能性についての考察が行われ、従来の手法と比較してLLMの利点が強調されています。
4. 課題と将来の方向性
本章では、LLMを判定者として活用する上での主要な課題と今後の研究の方向性について考察されています。以下の内容が含まれています:
- 現在の課題:バイアスの影響、モデルの透明性、解釈可能性といった技術的な課題が挙げられています。
- 未来の研究方向:LLMのさらなる改善、新しい評価基準の開発、他のAIシステムとの統合の可能性が提案されています。