目次
Harnessing Webpage UIs for Text-Rich Visual Understanding
この論文は、ウェブページのユーザーインターフェースから生成したマルチモーダル指示を利用して、テキスト豊富な視覚理解を向上させるための大規模データセット「MultiUI」を提案し、その効果を実証したものです。
論文:https://arxiv.org/abs/2410.13824
リポジトリ:https://neulab.github.io/MultiUI/
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、視覚的要素とテキストが密に統合された環境を処理する能力、すなわちテキストリッチな視覚理解を向上させるために、ウェブページのユーザーインターフェース(UI)から一般的なマルチモーダル指示を合成する手法を提案しています。提案されたMultiUIデータセットは、100万のウェブサイトからの730万のサンプルを含み、さまざまなマルチモーダルタスクとUIレイアウトをカバーしています。このデータセットを使って訓練されたモデルは、ウェブUIタスクで著しい性能向上を達成し、さらに非ウェブUIタスクやドキュメント理解、OCR、チャート解釈などの領域にも一般化できることが示されています。これにより、テキストリッチな視覚理解を進展させるためのウェブUIデータの広範な適用可能性が強調されます。最終的に、ウェブページの構造化データを活用することで、AIシステムがより効果的にデジタル環境と相互作用できることを目指しています。
この論文の特徴は、730万のマルチモーダル指示を含むMultiUIデータセットを用いて、ウェブページの構造化データから生成された指示が、AIモデルのドキュメント理解やOCR、チャート解釈などの非ウェブUIタスクにおいても優れた一般化能力を発揮する点です。
以下に、提供された情報を基にした論文の解説をまとめます。
論文解説
1. はじめに
1.1 背景と目的
テキストリッチな視覚理解とは、テキストと視覚要素が統合された環境を理解する能力を指します。これはマルチモーダル大規模言語モデル(MLLMs)にとって不可欠なスキルです。本研究は、ウェブページのユーザーインターフェース(UI)を利用し、この能力を向上させる新たなアプローチを提案します。具体的には、ウェブページのアクセシビリティツリーから構造化されたテキスト表現を生成し、これをUIのスクリーンショットと結びつけてモデルを訓練します。
1.2 研究のアプローチ
従来の手法は、視覚要素とテキストの複雑な関係を捉えることに限界がありました。本研究では、テキストベースのLLMsを用いてマルチモーダルな指示を生成し、より豊かなインタラクションを実現することを目指します。
2. データセット構築
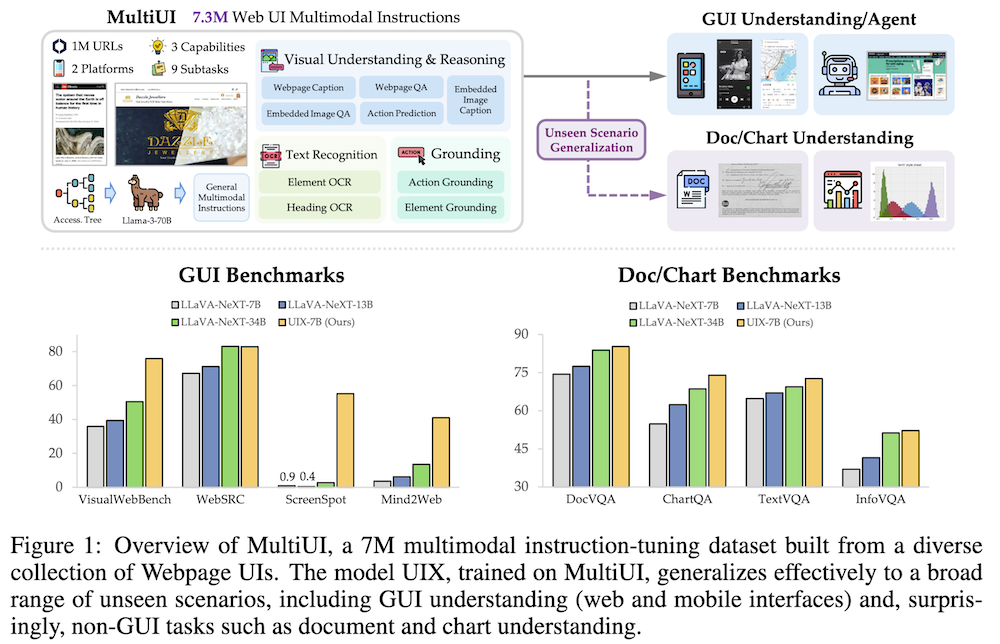
2.1 ウェブサイトの生データ収集
1.1百万件のウェブサイトから、生データを収集するための自動化されたパイプラインを構築しました。具体的には、HTML/CSS、ハイレゾリューションのスクリーンショット、アクセシビリティツリーを収集します。
2.2 ウェブサイトのキュレーション
収集したデータには不適切なコンテンツやネットワークエラーが含まれるため、フィルタリングモデルを用いて問題のあるウェブサイトを除外しました。この結果、最終的に約100万のウェブサイトがデータセットに残ります。
2.3 タスク抽出
収集したデータを基に、視覚理解、テキスト認識、グラウンディングのタスクを構築し、200種類の異なるプロンプトテンプレートを生成しました。
3. 実験設定
3.1 実装の詳細
Qwen2-7B-InstructをメインのLLMバックボーンとして使用し、他のモデルと組み合わせてデータセットの検証を行います。高解像度画像を処理するために、画像をパッチに分割して個別にエンコードする方法を採用しました。
3.2 ベンチマーク
モデルの能力を評価するために、GUI関連タスクやOCR関連タスクなど多様な評価ベンチマークを設定しました。
4. 実験結果と分析
4.1 GUI関連タスクでの結果
MultiUIデータセットを用いたモデルは、GUI理解やグラウンディングベンチマークでの性能が大幅に向上し、特にVisualWebBenchでは最大55.5%の改善を達成しました。
4.2 GUIエージェントタスクでの結果
Mind2Webタスクにおいて、提案したUIXモデルは既存のモデルを19.1%上回る精度を示しました。
4.3 文書理解とグラウンディングタスクでの結果
OCR関連のタスクでも顕著な改善が見られ、特に文書理解において非常に高いパフォーマンスを発揮しました。
5. 関連研究
本研究は、ウェブベースのマルチモーダルデータセットの収集方法や、MLLMによるGUI関連タスクの進展に関する既存の研究を参照し、提案手法の独自性を強調しています。
6. 結論
本研究では、ウェブページのUIを利用してテキストリッチな視覚理解を改善する手法を提案しました。構築したMultiUIデータセットは、さまざまなUIタイプとタスクを網羅しており、モデルの一般化能力を向上させることが確認されました。
付録
付録では、スクリーンショットのトリミングやアクセシビリティツリーの改善手法、タスク抽出のプロンプト例、トレーニングデータの詳細、評価ベンチマークの詳細などが示されています。