目次
OrionBench: A Benchmark for Chart and Human-Recognizable Object Detection in Infographics
この論文は、インフォグラフィックスにおけるチャートと人間が認識可能なオブジェクトの検出を支援するために設計された大規模なベンチマーク「OrionBench」を提案し、その有用性を示しています。
OrionBenchは、実際のインフォグラフィックと合成インフォグラフィックを組み合わせた大規模なデータセットを提供し、視覚言語モデルのチャート理解と物体検出能力を大幅に向上させるための新しい注釈手法を導入しています。
論文:https://arxiv.org/pdf/2505.17473
リポジトリ:https://github.com/OrionBench/OrionBench/

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
この論文では、科学、ビジネス、コミュニケーションの文脈におけるチャートの中心的な役割を踏まえ、視覚言語モデル(VLM)のチャート理解能力を向上させることの重要性が述べられています。既存のVLMの重要な制限は、インフォグラフィック要素、特にチャートやアイコン、画像などの人間が認識可能なオブジェクト(HRO)の視覚的グラウンディングが不正確であることです。しかし、チャートの理解には、関連する要素を特定し、それらに基づいて推論する能力が求められます。
この制限に対処するために、チャートとHROの正確な物体検出モデルの開発を支援することを目的に、OrionBenchというベンチマークを導入します。このベンチマークは、26,250の実際のインフォグラフィックと78,750の合成インフォグラフィックを含み、690万以上のバウンディングボックス注釈が付けられています。これらの注釈は、モデルインザループ法とプログラム的手法を組み合わせて作成されています。OrionBenchの有用性を示すために、3つのアプリケーションを通じて、1) VLMのチャート理解性能を向上させるThinking-with-Boxesスキームの構築、2) 既存の物体検出モデルの比較、3) 開発した検出モデルを文書レイアウトおよびUI要素検出に適用することを行います。
1. 導入
チャートは科学、ビジネス、コミュニケーション分野における重要な媒体であり、VLMsのチャート理解能力向上が急務となっている。実際のチャートは、アイコンや実世界オブジェクトの画像であるhuman-recognizable objects(HROs)と組み合わされてインフォグラフィックを形成する。しかし、既存のVLMsは、チャートとHROsの不正確なvisual groundingに制限があり、要素とデータの関連付けを阻害している。テキスト検出は進歩しているが、抽象データと人間の認識を結ぶチャート・HRO検出は十分に探索されていない。本研究は、多様性と正確な注釈を持つ大規模ベンチマークの必要性を指摘し、OrionBenchを提案する。
2. 関連研究
HROsの存在に基づき、要素注釈付きチャートデータセットはプレーンチャートとインフォグラフィックチャートに分類される。プレーンチャートデータセットには、Bokehを用いたFigureQAなどのプログラマティック作成データセットと、IEEE VIS出版物から収集したVisImagesなどの既存文献・オンラインプラットフォーム収集データセットがある。しかし、これらのモデルは多様なHROsとチャートの相互作用によって生じる大きな変動を持つインフォグラフィックスでは困難を抱える。Borkin et al.は豊富な注釈を持つインフォグラフィックデータセットを先駆的に作成したが、労働集約的な手動注釈プロセスにより393サンプルに限定されており、汎化性能を要求するオブジェクト検出モデル訓練には不適切である。
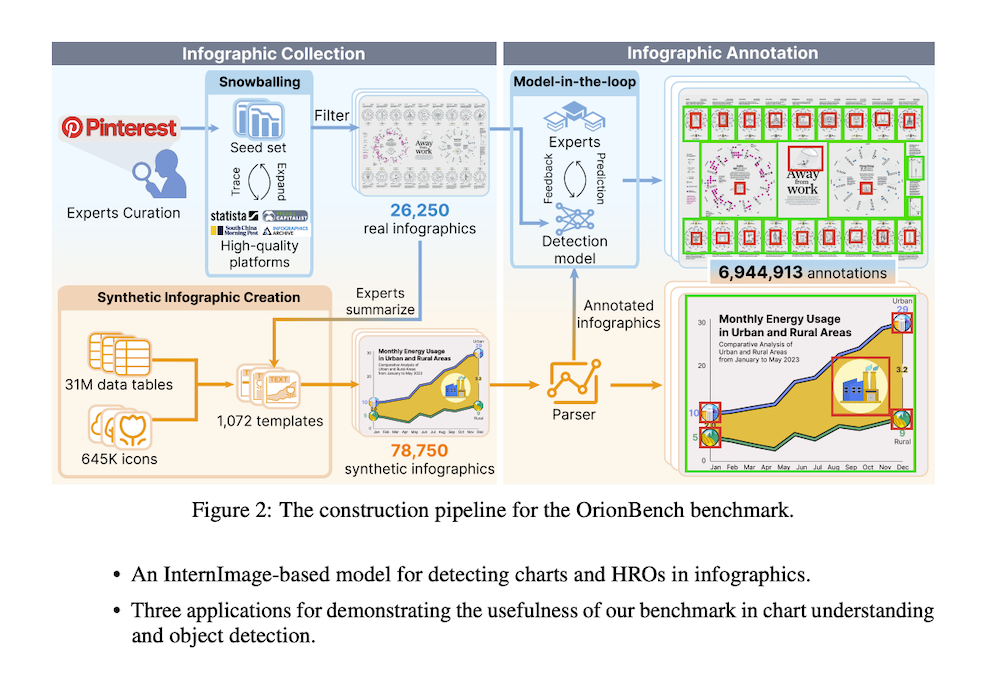
3. OrionBench構築手法
本手法は、インフォグラフィック収集とインフォグラフィック注釈の2つのステップで構成される。実データと合成データの相補的利点(前者は真正なデザイン実践、後者は制御された変動とスケーラビリティ)を活用し、オンラインプラットフォームからの実インフォグラフィックとデザインテンプレートからプログラマティックに作成された合成インフォグラフィックの2つのソースから収集する。
3.1 インフォグラフィック収集
実インフォグラフィック収集: キーワードベース検索の不適切性を解決するため、デザイン専門家によって厳選された高品質インフォグラフィックのシードセットから開始し、snowballing手法を開発した。この手法は、(1)プラットフォーム推薦機能を利用したautomatic forward snowballing、(2)シードインフォグラフィックの出典を追跡してソース多様性を増加させるmanual backward snowballingの2つの補完ステップで構成される。Pinterestを含む7つのオンラインプラットフォームから219,463のインフォグラフィックを収集し、重複除去とGPT-4o miniによる視覚的品質検証により26,250の高品質インフォグラフィックに精製した。
合成インフォグラフィック作成: 代表的な実インフォグラフィックから派生した1,072のデザインテンプレートを利用したtemplate-based手法を採用した。各テンプレートは、(1)チャート、テキスト、HROsの存在と相対位置、(2)チャートの種類と視覚スタイルを指定する。VizNetから3100万テーブルを含むデータテーブルをサンプリングし、GPT-4o miniで記述テキストを生成し、IconQAデータセットから645K個のアイコンを用いてHROsを選択することで、78,750の合成インフォグラフィックを生成した。
3.2 インフォグラフィック注釈
実データと合成データの収集方法の違いを考慮し、合成インフォグラフィック用のプログラマティック手法と実インフォグラフィック用のmodel-in-the-loop手法を採用した。
プログラマティック合成インフォグラフィック注釈: インフォグラフィック生成プロセスに統合されたパーサーでプログラマティックに生成される。このパーサーは、インフォグラフィックの視覚的・構造的詳細をエンコードするSVGファイルからテキスト、チャート、HROsのバウンディングボックスを抽出する。デザインテンプレートからの情報を活用し、チャートを67の異なるタイプに分類し、HROsをデータ関連またはテーマ関連オブジェクトとしてラベル付けする。
Model-in-the-loop実インフォグラフィック注釈: 注釈作業での人的労力削減を目的とし、オブジェクト検出モデルとの協力的開発手法を採用した。注釈付き合成インフォグラフィックを用いて、InternImage-LをDINO検出器と共にファインチューニングすることでオブジェクト検出モデルを構築した。このモデルで全実インフォグラフィックの注釈を生成し、専門家による複数ラウンドの注釈改良とモデル強化を実施した。最終的に生成された注釈は93.9%の精度と96.7%の再現率を達成した。
3.3 統計
OrionBenchは26,250の実インフォグラフィックと78,750の合成インフォグラフィックを含む105,000のインフォグラフィックで構成される。PP-OCRv4を用いてテキスト注釈を補完し、合計5,789,902のテキスト、245,137のチャート、909,874のHROsを注釈した。一貫した評価のため、訓練セット100,000、テストセット5,000に分割し、両セットで実・合成インフォグラフィックの比率を維持した。
4. 実験
最新VLMsの性能向上のためThinking-with-Boxesスキームを構築し、既存オブジェクト検出モデルの性能評価を行い、InternImageベースオブジェクト検出モデルをグラフィックレイアウト検出タスクに適用した。
4.1 グラウンデッド思考連鎖によるThinking-with-Boxes
最新のVLMs(OpenAIのo3/o4-mini)は、自動ズームや切り抜きなどのシームレスな画像操作を通じてchain-of-thought推論能力を示す。チャート理解には、インフォグラフィック画像内の要素に対するより複雑で細粒度の視覚推論が本質的に必要であることを考慮し、Thinking-with-Boxesスキームを構築した。このスキームは、インフォグラフィック指向オブジェクト検出モデルとOCRモデルで予測されたテキスト、チャート、HROsのグラウンデッド注釈と追加の層化インフォグラフィック画像を明示的に提供してVLMsを強化する。
4.1.1 グラウンデッド思考連鎖プロンプティング
複雑な理解タスクを、インフォグラフィック要素に対するステップバイステップ推論に分解する。検出された要素を2つのモダリティで提供:(1)インフォグラフィック画像にボックスをオーバーレイする視覚プロンプト、(2)各要素のテキスト記述。視覚プロンプトでは、アルファベットIDでラベル付けされたバウンディングボックスをオーバーレイし、背景との対比色で明瞭性を向上させる。密なテキストとHROsの領域での重複を軽減するため、チャート・HROsレイヤーとテキストレイヤーの2層に分離することを提案した。
4.1.2 実験設定
ChartQAProベンチマークを用いて1,341画像にわたる1,948の challenging question-answer pairsでVLMsのチャート理解能力を評価した。プレーン/インフォグラフィック、単一/複数チャートの2つの基準に基づき4グループに手動分類した。OpenAIのo1、o3、o4-miniの3つの最新VLMsを評価し、Direct prompting、Chain-of-Thought(CoT)、Program-of-Thought(PoT)の3つのベースライン手法と比較した。
4.1.3 結果と分析
グラウンデッドCoTプロンプティングの有効性: 最新VLMsへのステップバイステップ思考やPythonコード記述のプロンプトは性能を大幅に改善しない。これは推論中心設計により明示的なステップバイステップ推論プロンプトへの依存が本質的に削減されているためと考えられる。対照的に、本手法はグラウンデッドインフォグラフィック要素を提供することでチャート理解性能を向上させる。特にプレーン単一チャートでは同等の性能を示し、インフォグラフィックチャートと複数チャート画像でより良い性能を示す。
アブレーション研究: (1)視覚プロンプトまたはテキスト記述のみの使用は両者の組み合わせと比較して性能低下をもたらし、インフォグラフィック要素のグラウンディングとチャート理解支援における相補的役割を強調する。(2)プロンプトの2層分離は1層提供より良い性能をもたらし、分離による重複削減がインフォグラフィック要素の視覚グラウンディングを促進することを示唆する。(3)文脈内例の組み込みは性能低下をもたらし、最新VLMsが追加例なしで効果的に推論タスクを実行できることを示す。
4.2 オブジェクト検出モデルの評価
チャートとHRO検出におけるOrionBenchでの11のオブジェクト検出モデルの性能を比較し、訓練サンプル数と実・合成インフォグラフィックの比率による性能変動を分析した。
4.2.1 実験設定
モデル: 訓練・推論パラダイムに基づき、zero-/few-shot検出をサポートするfoundationモデルと新規クラス検出前にファインチューニングを要求する従来型深層学習モデルに分類される。7つのfoundationモデル(RegionCLIP、Detic、Grounding DINO、GLIP、MQ-GLIP、T-Rex2、DINO-X)と4つの従来型モデル(Faster R-CNN、YOLOv3、RTMDet、Co-DETR)を選択した。
評価プロトコル: 3つの適応手法を評価:(1)テキストプロンプトで対象クラスを定義するZero-shot prompting、(2)k個のランダム選択インフォグラフィックで対象クラスを記述するFew-shot prompting、(3)注釈付きインフォグラフィックでモデル重みを更新するStandard fine-tuning。
4.2.2 結果と分析
適応手法とオブジェクト検出モデルの比較: Zero-shotとfew-shot promptingは限定的性能を示す。DINO-Xなどの最新foundationモデルでもテキストプロンプトを通じたこれらの概念解釈に失敗し、重要コンポーネントを見落とすことが多い。注釈付き例インフォグラフィックの提供も顕著な性能向上をもたらさない。これは自然シーン事前訓練によるインフォグラフィックなどのグラフィック表現への限定的露出に起因する。
Standard fine-tuningは性能を改善する。例インフォグラフィックとOrionBench訓練セットでのファインチューニングはzero-/few-shot promptingと比較して改善された性能を達成する。OrionBenchでファインチューニングされた全従来型モデルは例インフォグラフィックのみで訓練された対応モデルを上回る。Co-DETRがチャート90.1、HRO86.0の最高APを達成し、両要素検出の課題に効果的に対処した。
訓練セットサイズと混合比率のアブレーション: Faster R-CNNを用いたアブレーション研究で、データセットサイズ(n=200, 1000, 5000, 25000)と実インフォグラフィック比率(q=0〜1、0.2刻み)を変動させた。実または合成インフォグラフィックのみの訓練は高速な性能飽和をもたらすが、両者の組み合わせはこの効果を軽減し、データセット拡張とともに一貫した性能向上を実現する。
4.3 開発モデルのグラフィックレイアウト検出への適用
OrionBenchの広範な適用可能性を実証するため、InternImageベースモデルをRicoとDocGenomeでのグラフィックレイアウト検出タスクに適用した。
4.3.1 実験設定
RicoはAndroidアプリケーションから収集された66K以上のユーザーインターフェースを含み、25のUIコンポーネントクラス検出を目的として53K訓練用、13K評価用に分割した。DocGenomeはarXivリポジトリから取得された6.8M科学文書ページの大規模データセットで、13カテゴリのコンポーネント用バウンディングボックス注釈を持つ。113K訓練用、13K評価用に分割した。
4.3.2 結果と分析
OrionBenchでの事前訓練は、RicoとDocGenomeでファインチューニング時のモデル性能を向上させ、グラフィックレイアウト検出強化におけるOrionBenchの有効性を実証した。foundationモデル訓練への複数データセット統合への関心の高まりとともに、OrionBenchはグラフィックレイアウト検出用既存リソースへの有用な追加となる。
5. 結論
本論文は、インフォグラフィックにおけるチャートとHRO検出をサポートするベンチマークOrionBenchを導入した。実・合成インフォグラフィックの多様な収集とテキスト、チャート、HROs用バウンディングボックス注釈を特徴とする。3つの応用により、このベンチマークが視覚推論手法開発に価値があるだけでなく、オブジェクト検出評価やグラフィックレイアウト分析などのタスクに広く適用可能であることを実証した。OrionBenchは効果的であることが証明されているが、将来の研究方向として、チャート内の軸ラベルやデータポイントなどのより細粒度注釈の追加、デザイン原理発見のための多様なインフォグラフィック収集分析による自動インフォグラフィックデザインの進歩が残されている。