目次
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
この論文は、視覚的文書理解のために適応的なマークアップ言語生成を提案し、多様な文書タイプに対する文脈に基づいた理解を向上させる手法を紹介しています。
この論文は、視覚文書の理解を強化するために、マークアップ言語の適応生成を利用して文脈に基づいた応答を提供し、複雑な文書形式に対する推論能力を大幅に向上させる新しいパイプラインを提案しています。
論文:https://arxiv.org/abs/2505.05446
リポジトリ:https://github.com/Euphoria16/DocMark

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
視覚文書理解は、テキストが豊富な視覚コンテンツの増加に伴い、重要性を増しています。この分野は、特に複雑なレイアウトを持つ多様な文書タイプ間での視覚的知覚とテキストの理解を効果的に統合する必要があるため、重要な課題を提起します。さらに、この分野の既存のファインチューニングデータセットは、堅牢な理解を提供するための詳細な文脈情報が不足していることが多く、これが幻覚や視覚要素間の空間関係の理解の限界を招いています。
これらの課題に対処するため、我々は、Markdown、JSON、HTML、TiKZなどのマークアップ言語の適応生成を利用して、高度に構造化された文書表現を構築し、文脈に基づいた応答を提供する革新的なパイプラインを提案します。文書解析用の約3.8Mの事前学習データペアを含むDocMark-Pileと、地に基づく指示に従った624kのファインチューニングデータ注釈を特徴とするDocMark-Instructという2つの細分化された構造データセットを紹介します。広範な実験により、我々の提案したモデルが、複雑な視覚シナリオにおける高度な推論と理解能力を促進し、視覚文書理解のベンチマークにおいて既存の最先端のMLLMを大幅に上回ることを示しました。
1. はじめに
テキストが豊富な視覚コンテンツは日常生活に遍在し、視覚的文書理解は基本的なタスクとなっています。これは視覚認識とテキスト理解の統合や、これらのモダリティ間の複雑な相互作用のナビゲーション能力を必要とします。マルチモーダル大規模言語モデル(MLLM)は進歩しているものの、課題は視覚コンテンツとレイアウト情報の効率的な表現と効果的な認識にあります。一般的な微調整データセットは質問と簡潔な回答のみを含み、文書の様々な部分を理解する必要があるにもかかわらず、回答はしばしば短いフレーズや単一の数値で構成されています。本研究では、MLLMによるマークアップ言語の適応的生成を提案し、様々な文書タイプの包括的理解と明示的なコンテキスト提供を促進します。
2. 関連研究
2.1. マルチモーダル大規模言語モデル(MLLM)
自然言語処理分野は大規模言語モデル(LLM)の登場により大きく進展しました。OpenAIのGPTシリーズは、数十億から数兆のパラメータを持つ大規模なモデルスケーリングの力を活用しています。指示追従能力を向上させるために、InstructGPTやChatGPTなどのモデルが開発され、オープンドメインの会話タスクで優れた流暢さと汎用性を示しています。最近の研究はLLMをマルチモーダルタスクに応用し、Linear ProjectorやQFormerを適用して視覚エンコーダの出力をLLMのテキスト特徴空間に合わせています。しかし、既存手法は視覚表現の限界により、包括的なシーン理解に苦戦しています。本論文ではこのギャップを埋めるために、明示的なコンテキスト情報を生成する適応型マークアップ生成パイプラインを設計します。
2.2. 視覚的文書理解
最近のMLLMの進歩により、文書画像の自己回帰訓練を用いて視覚的文書理解タスクが大幅に向上しています。UReaderはShape-adaptive Cropping Moduleを導入し、高解像度画像を低解像度のサブ画像に分割してテキスト情報を効果的に捉えています。Monkeyは同じ文書の異なるビュー間の冗長性を最小化するスライディングウィンドウアプローチを利用しています。DocOwl 1.5、LLaVA-Next、InternVLなどのモデルはOCR事前学習と動的分割技術を探索し、様々なアスペクト比に対応しています。LLaVA-Readは二重解像度画像と追加のOCRエンコーダを統合してテキスト情報のエンコーディングを改善しています。DocPediaやCogAgentなどの他のアプローチは、視覚表現を強化するために多様なエンコーディング戦略を採用しています。私たちは、マークアップ言語解析と推論タスクを通じて文脈に根ざしたトレーニングデータを開発し、構造化された文書表現でトレーニングすることで、LLMのコード解釈能力を活用して視覚的文書理解をさらに強化します。
3. 方法
3.1. DocMark-Pile: マークアップ言語変換のためのマルチタスク事前学習
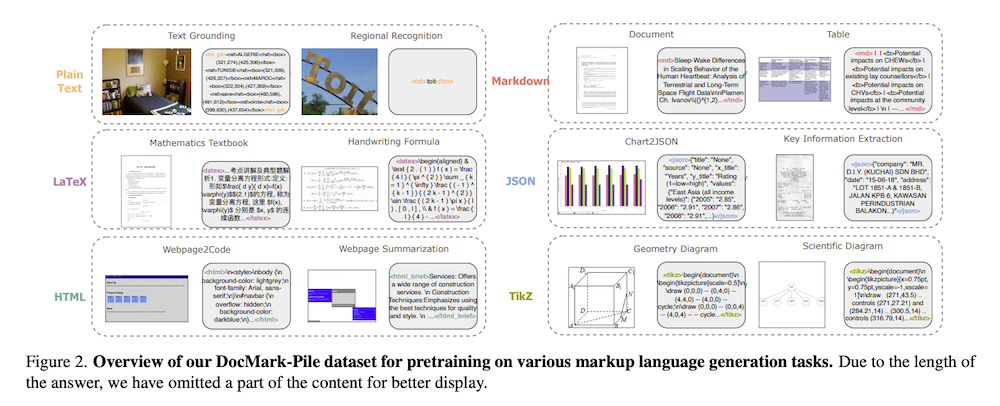
視覚的文書理解にはPDF文書からの段落理解、チャートやテーブルの数値データ解釈、レシートからの情報取得など様々なタスクが含まれます。ほとんどの文書はソースコードから生成されているか、構造化された表現に変換できます。これらの構造化されたフォーマットはマークアップ言語として機能し、要素の構造を定義し、内容の効果的な伝達と整理を支援します。様々な視覚的文書タイプを理解し解釈するモデルの能力を向上させるために、文書を対応するマークアップ言語に変換することに焦点を当てたマルチタスク事前学習データセット「DocMark-Pile」を提案します。文書理解シナリオを包括的にカバーするために、プレーンテキスト、マークダウン、LaTeX、HTML、JSON、TiKZの6つの異なるマークアップ言語を利用します。
3.1.1 専門的なタスク設計
文書からTXT: プレーンテキストは自然写真や地域テキスト画像からの基本的なコンテンツ抽出に最適です。TextOCR、COCO-Text、HierText、LSVT、RCTW-17、CTW1500などの公開データセットを活用し、広告ポスター、看板、製品ラベル、画像字幕など幅広いシナリオをカバーしています。
文書からMarkdown: Markdownは密なテキスト文書とテーブルに効果的で、太字、斜体、見出し、リストなどの基本的なフォーマットオプションを提供します。arXivからの記事や、PubTabNet、SynthTabNet、TabRecSet、TableGraph、SciTSRなどのテーブルデータセットを主なソースとしています。
文書からLaTeX: LaTeXは複雑な数式や科学的表記を精密にモデル化できるため、数学や科学の教科書や試験問題からのイメージに使用されます。Mathpixを使用して注釈を生成し、HME100KやMathWritingなどの手書き数式認識データセットも含めています。
文書からHTML: ウェブページ理解のために、WebSightなどのHTML形式へのウェブページ解析タスクを導入しています。実際のウェブサイト画像とHTMLコードをスクレイピングし、主要素のみを抽出するウェブページ要約タスクも追加しています。
文書からJSON: 構造化情報抽出のためにJSONフォーマットを利用し、キーと値のペアとして情報を表現します。これはカード、レシート、フォームからの名前、日付、住所などの要約や取得に特に有効です。CORD、POIE、SVRD、WildReceipt、XFUNDなどの公開データセットを活用しています。
文書からTikZ: TikZは科学的な図の作成に一般的に使用されるマークアップ言語です。DaTikZv1とDaTikZv2のオープンソーストレーニングセットを活用し、arXiv論文から収集されたTikZグラフィックと人工的な例、およびそれらに対応するTikZプログラムを含んでいます。
3.1.2 データセット統計
DocMark-Pileは多様なマークアップ言語解析タスクと画像タイプの380万例からなる包括的なデータセットです。マークアップ言語のカテゴリー分布とイメージタイプの分布を図3で示しています。
3.2. 微調整中の適応型マークアップ言語生成
3.2.1 適応型生成パイプライン
多様なマークアップ言語生成のためのマルチタスク事前学習を通じて、モデルは多様な文書の視覚コンテンツとレイアウト情報を理解する能力が向上します。さらに指示調整データセットを使用してモデルを微調整し、文書コンテキストに関連するオープンエンドの質問応答などのダウンストリームタスクを処理する能力を備えています。私たちのモデルの構造化されたマークアップ言語生成能力は大きな利点を提供し、これらの生成されたマークアップ言語は複雑な推論タスクを促進する補助的なコンテキスト手がかりとして機能します。
LLMで広く採用されているChain-of-Thought推論に触発されて、推論能力を向上させるための適応型マークアップ言語生成パイプラインを設計しました。事前学習モデルによって生成するマークアップ言語のタイプを手動で決定するのではなく、モデルが回答を導き出すための中間ステップとして適切なマークアップ言語を自動的に生成できるようにしています。これは人間のような思考のチェーン推論を反映しています。
3.2.2 DocMark-Instruct: CoT推論データ構築
テンプレート(1)で説明されているようにフォーマットされたデータセットを提供するため、「DocMark-Instruct」という必要なデータを構築するための効率的な方法を提案しています。まず事前学習済みモデルを使用して画像を対応するマークアップ言語に変換し、次にChatGPT-3.5を用いて追加の注釈を作成します。質問-回答ペアとマークアップ言語テキスト全体を入力し、質問に答えるために必要な情報を取得するよう求め、最終的に62.4万件の注釈を生成しています。
3.2.3 訓練と推論
微調整フェーズでは、2ラウンドの対話データを連結してフォワードプロセスに使用し、両方の回答(A1とA2)にクロスエントロピー損失を適用します。推論フェーズでは、まずQ1を入力してモデルに適応型マークアップ言語コンテキストを生成するように促し、その後Q2を入力して最終的な応答を得ます。このトレーニングパイプラインはCoT推論プロセスがない一般的なトレーニングデータとも互換性があります。
4. 実験
4.1. 実装の詳細
モデルアーキテクチャ: 視覚表現能力が向上しているInternVLアーキテクチャを採用し、視覚エンコーダーとしてInternViT、言語理解能力の高いInternLM-2BとInternLM-8Bを使用しています。MLPレイヤーを使用して画像を視覚トークンに投影し、テキストトークンと連結しています。InternVL2で提案された動的解像度手法を採用し、高解像度文書画像のモデリングに効果を示しています。
トレーニング設定: モデルは2段階のプロセスでトレーニングされています。最初の段階では、DocMark-Pileを使用してモデルにマークアップ言語解析能力を付与し、視覚入力とテキストトークン間のアライメントを確保するためにLLaVA-558K画像キャプションデータセットも組み込んでいます。2e-5の学習率で、バッチサイズ128で1エポックの事前トレーニングを行います。第二段階では、提案したCoT推論データセットDocMark-Instructでモデルを微調整します。
4.2. マークアップ言語生成能力の評価
モデルのマークアップ言語生成能力を包括的に評価し、ドメインエキスパートモデルと比較しました。シーンテキスト認識([38]のベンチマーク)、LaTeX形式の数式表現(HME100K[72]のテストセット)、ChartQA-SE[5]ベンチマーク(AP@strict、AP@slight、AP@high指標)、キー情報抽出(FUNSDとSROIE)、TiKZコード生成(DaTikZテストセット[2])で評価しています。DocMarkモデルはテキスト認識とHME100Kベンチマークでエキスパートモデルを大幅に上回り、ChartQA-SEとKIEタスクの構造情報抽出でも印象的な能力を示しています。
4.3. ダウンストリーム理解タスクの評価
適応型マークアップ言語生成の有効性を検証するために、文書理解のダウンストリームタスクの範囲でモデルの性能を評価しました。様々なマルチモーダルシナリオを包含する多様な評価ベンチマークを採用しています。TextVQA[55]、DocVQA[44]、InfoVQA[43]、AI2D[24]、ChartQA[42]、OCRBench[38]、VisualWebBench[37]のWebQA精度、MathVision[62]での数学的推論性能を評価しています。DocMarkモデルは2Bと7Bパラメータサイズの両方で、ほぼすべてのベンチマークで最先端のマルチモーダル大規模言語モデルを一貫して上回っています。
4.4. アブレーション研究
提案されたデータセットの影響を調査するために、DocMark-2Bを使用して様々なトレーニングデータセット戦略を検討しました。DocMark-PileとDocMark-Instructを組み込まずに、画像キャプションデータセットと一般的な質問回答データセットのみに依存してモデルをトレーニングし、4つの文書関連QAデータセットでモデルの精度を報告しています。DocMark-Pileがないと、特にテキストが密な文書や構造化データに対するモデルのパフォーマンスが大幅に低下します。さらに、DocMark-Pileの事前トレーニングの上にDocMark-Instructを組み込むことで、推論能力の向上においてその有効性が実証されています。
5. 結論
本論文では、視覚的文書理解を強化するために適応型マークアップ言語生成を活用する革新的なフレームワークを紹介しました。提案されたアプローチは、専門的な事前トレーニングタスクと適応型生成パイプラインを組み込むことで、視覚コンテンツとレイアウト情報を効率的に表現し認識するという核心的な課題に対処しています。広範な実験により、モデルがいくつかの困難な視覚的文書理解タスクで既存の最先端アプローチを上回ることが実証されました。