目次
Performance Evaluation of Emotion Classification in Japanese Using RoBERTa and DeBERTa
この論文は、日本語のテキストにおける感情分類の精度評価を行い、特にDeBERTa-v3-largeモデルが最も優れた性能を発揮することを示しています。
この研究では、DeBERTa-v3-largeモデルが日本語の感情分類において高い精度を実現し、特に低頻度の感情でも安定した性能を発揮する点が革新的である。
論文:https://arxiv.org/abs/2505.00013
リポジトリ:https://huggingface.co/YoichiTakenaka/deverta-v3-japanese-large-Joy

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
概要
この研究は、日本語のテキストにおける感情検出のための高精度モデルの構築を目的としています。具体的には、プルチックの八つの感情の存在または不在を予測するモデルを開発します。WRIMEコーパスを使用して、読み手の平均的な強度スコアをバイナリラベルに変換し、BERT、RoBERTa、DeBERTa-v3-base、DeBERTa-v3-largeの4つの事前学習済み言語モデルをファインチューニングします。また、文脈を考慮して、TinySwallow-1.5B-InstructとChatGPT-4oの2つの大規模言語モデルも評価します。評価指標としては、精度とF1スコアを用います。
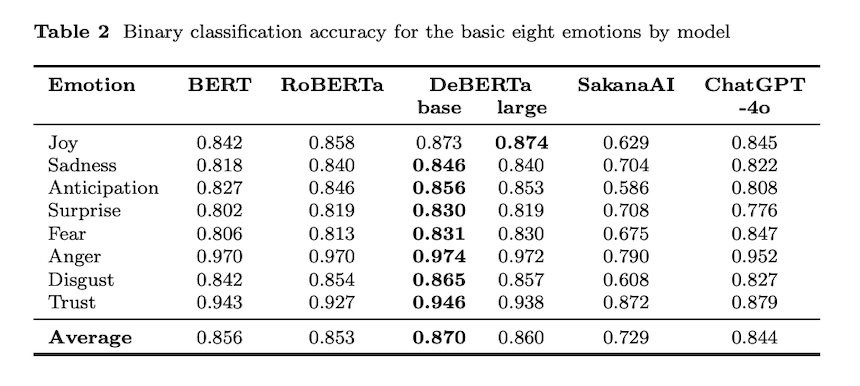
DeBERTa-v3-largeは最も高い平均精度(0.860)とF1スコア(0.662)を達成し、他のすべてのモデルを上回ります。高頻度の感情(例:喜び、期待)と低頻度の感情(例:怒り、信頼)においても堅牢なF1スコアを維持しています。一方、LLMは遅れを取り、ChatGPT-4oとTinySwallow-1.5B-Instructはそれぞれ平均F1で0.527と0.292のスコアを記録しました。ファインチューニングされたDeBERTa-v3-largeモデルは、現在、日本語のバイナリ感情分類において最も信頼性の高いソリューションを提供します。
1. 序論
感情分析はテキストから人間の感情を抽出・分類するNLP技術で、ソーシャルメディア分析から顧客レビュー理解まで幅広く応用されています。従来の極性分類(ポジティブ/ネガティブ/中立)に対し、プルチックの感情理論は8つの基本カテゴリでより細かい枠組みを提供。日本語感情分析は英語に比べデータセット・研究蓄積で遅れがあります。本研究ではWRIMEコーパスを用い、BERTの改良版RoBERTaとDeBERTaを評価し、日本語特有の感情分類課題への対応を検証しました。
2. データセット
2.1 WRIMEデータセットの概要
WRIMEは日本語感情分析用コーパスで、ソーシャルメディア投稿に2種類のラベル(書き手の自己報告感情と第三者評価感情)が付与されています。書き手と読者の感情認識ギャップを定量化できる二重注釈設計を採用。各投稿にプルチックの8感情(喜び、悲しみ、期待、驚き、恐怖、怒り、嫌悪、信頼)について0〜3の強度スコアが割り当てられており、本研究では43,000件の投稿を使用しました。
2.2 感情強度分布とクラス不均衡
WRIMEデータの感情強度分布を分析すると、全感情で「感情なし」(強度0)が支配的です。「喜び」で69%、「怒り」では97%が強度0であり、少数クラス(強度≧1)サンプルが極端に少ないためモデル学習に課題があります。この不均衡問題を軽減するため、本研究では「感情あり」(強度≧1)対「感情なし」(強度0)の二値分類問題として再設定しました。
3. 方法
本研究では、8つの独立した二値分類問題を設定。プルチック各感情について日本語文での存在/不在を予測します。WRIMEコーパスから得られた読者平均強度スコアを二値ラベルに変換し、4つの日本語PLM(BERT、RoBERTa、DeBERTa-v3-base、DeBERTa-v3-large)を微調整。データは80%訓練・20%テスト分割で、Hugging Face Transformersライブラリを使用しました。比較対象として、TinySwallowとChatGPT-4oをプロンプト方式で評価。評価指標には精度とF1スコアを採用しました。
4. 結果
すべての感情において、DeBERTaファミリーが最高精度を達成。DeBERTa-v3-baseとlargeの平均精度はそれぞれ0.870と0.860で、他のモデルを上回りました。F1スコアでは、DeBERTa-v3-largeが「喜び」を除く7感情で最高値を記録。「喜び」はChatGPT-4oが優位でした。全体平均F1スコアはDeBERTa-v3-large(0.662)、ChatGPT-4o(0.527)、TinySwallow(0.292)の順となり、PLMsがLLMsを大きく上回る結果となりました。
5. 考察
DeBERTa-v3-baseとDeBERTa-v3-largeが全感情で最高/準最高精度を達成し、最近のPLM建築改良が感情検出タスクでも明確な利益をもたらすことを示しました。F1スコアでもDeBERTa-v3-largeが7/8感情で最高値を記録。高頻度感情(悲しみ、期待)と低頻度感情(怒り、信頼)の両方で強いパフォーマンスを示しました。PLMsとLLMsの比較では、すべてのPLMsがF1スコアでLLMsを上回り、特にTinySwallowは複数感情で0.1未満と低迷。現状ではRoBERTa/DeBERTaバリアント、特にDeBERTa-v3-largeが日本語感情分類に最適です。
6. 結論
本研究では8つの二値感情分類器を開発し、日本語PLMsをWRIMEコーパスで評価しました。DeBERTa-v3-largeが最強パフォーマンス(F1:0.662)を示し、ChatGPT-4o(0.527)とTinySwallow(0.292)を上回りました。日本語感情分析には現時点でPLMsのタスク特化型微調整が最適解です。今後は低頻度感情分類の改善、モデル軽量化、LLMパフォーマンス向上のプロンプト技術研究が課題となります。本研究は日本語感情分析のモデル設計ガイドラインと経験的ベンチマークを提供し、多言語・多感情処理研究の基盤を築きました。