目次
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
この論文は、UI-TARSという新しいネイティブGUIエージェントモデルを提案し、スクリーンショットを入力として人間のようにGUIと対話し、さまざまなタスクを効率的に実行する能力を示しています。
UI-TARSは、従来のモジュール型エージェントフレームワークに代わるエンドツーエンドモデルであり、GUIタスクにおける知覚、推論、行動の統合を実現し、複雑な操作を人間に近い形で自律的に行う能力を持っている点が特徴です。
論文:https://arxiv.org/abs/2501.12326
リポジトリ:https://github.com/bytedance/UI-TARS
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
この論文では、UI-TARSというネイティブGUIエージェントモデルを紹介します。このモデルは、スクリーンショットを入力として認識し、人間のような操作(例:キーボードやマウスの操作)を実行します。従来のエージェントフレームワークが専門家によって作成されたプロンプトやワークフローに依存しているのに対し、UI-TARSはエンドツーエンドのモデルであり、これらの高度なフレームワークを上回る性能を示します。
実験により、UI-TARSは知覚、基盤、GUIタスク実行を評価する10以上のGUIエージェントベンチマークで最先端のパフォーマンスを達成していることが示されています。特に、OSWorldベンチマークでは、UI-TARSは50ステップで24.6、15ステップで22.7のスコアを達成し、Claudeのそれぞれ22.0と14.9を上回りました。AndroidWorldでは、UI-TARSは46.6を達成し、GPT-4oの34.5を超えています。
UI-TARSは、(1)強化された知覚:GUIスクリーンショットの大規模データセットを活用し、UI要素の文脈に応じた理解と正確なキャプションを実現、(2)統一されたアクションモデリング:プラットフォーム間でアクションを統一された空間に標準化し、大規模なアクショントレースを通じて正確な基盤と相互作用を達成、(3)システム2の推論:多段階の意思決定に意図的な推論を組み込み、タスクの分解、反省思考、マイルストーン認識などの複数の推論パターンを含む、(4)反射的オンライントレースによる反復的トレーニング:データボトルネックに対処し、数百の仮想マシンで新しい相互作用トレースを自動的に収集、フィルタリング、反省的に洗練します。
反復的なトレーニングと反射調整を通じて、UI-TARSは自らの誤りから継続的に学習し、最小限の人間の介入で予期しない状況に適応します。また、GUIエージェントの進化の道筋を分析し、この分野のさらなる発展を導くためのガイドを提供します。
要約
1. はじめに
1.1 自律エージェントの重要性
自律エージェントは、最小限の人間の監視のもとで環境を認識し、意思決定を行い、特定の目標を達成するために行動することが期待されています。特に、グラフィカルユーザーインターフェース(GUI)とのシームレスな相互作用が、新しい技術的課題として重要視されています。
2. GUIエージェントの進化
2.1 ルールベースエージェント
初期のルールベースエージェントは、定義されたルールに基づいて動作し、特定の指示に従いましたが、柔軟性が欠如しており、新しいシナリオには対応しきれませんでした。
2.2 モジュラーエージェントフレームワークからネイティブエージェントモデルへ
モジュラーエージェントフレームワークは特定のタスクに特化していましたが、柔軟性とスケーラビリティに限界がありました。これに対し、ネイティブエージェントモデルは、エンドツーエンドで学習・実行できるため、一般化されたタスクに対応可能となります。
2.3 アクティブおよび生涯学習エージェント
将来的には、エージェントが自己主導でタスクを提案し、実行し、結果を評価する能力を持つことが求められます。
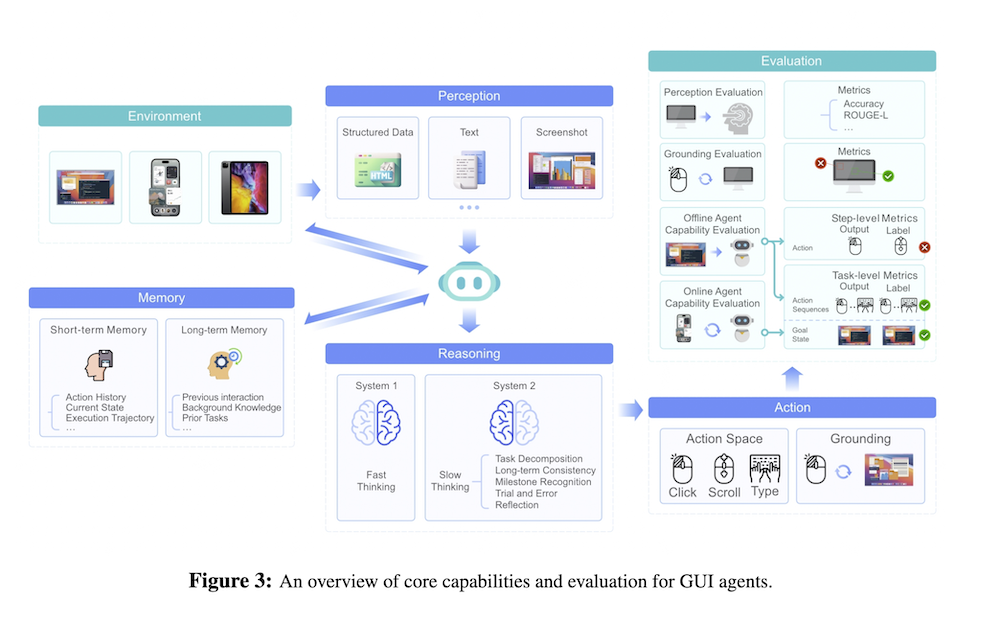
3. ネイティブエージェントモデルのコア能力
3.1 コア能力
ネイティブエージェントモデルは、知覚、行動、推論(システム1とシステム2)、メモリの4つのコア能力を持つ必要があります。これにより、効果的なタスク遂行が可能となります。
3.2 能力評価
エージェントの能力は、知覚能力とグラウンディング能力を評価するための指標やベンチマークを用いて測定されます。
4. UI-TARS
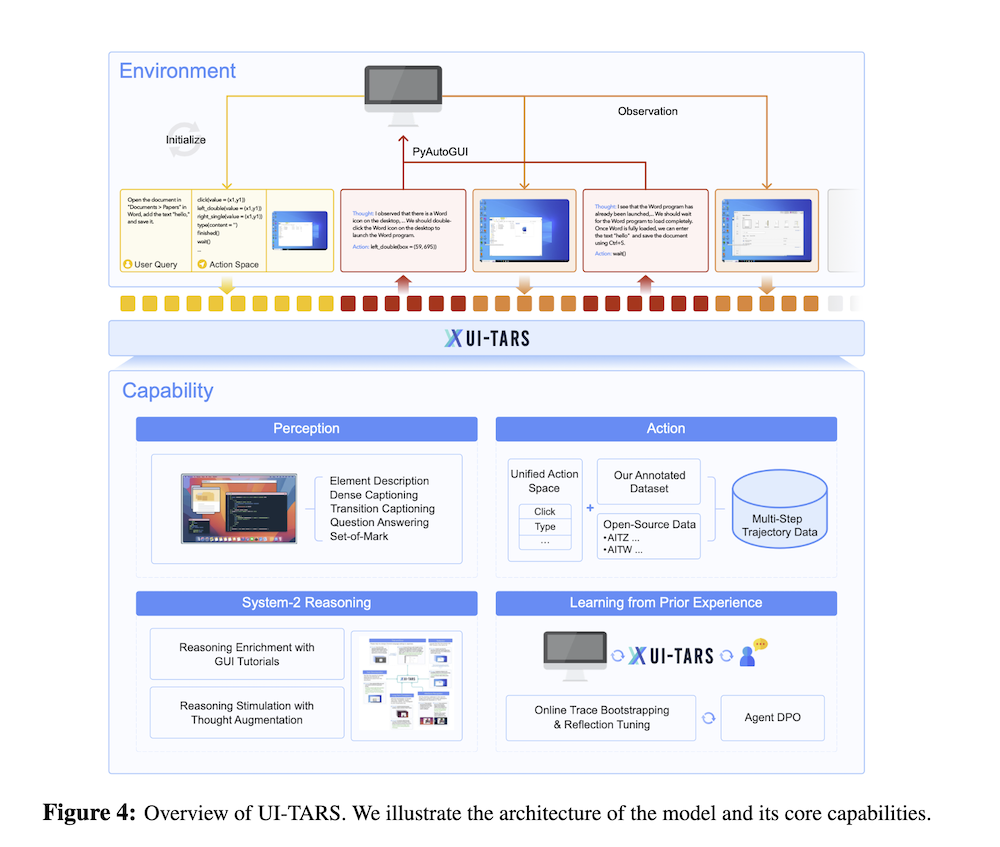
4.1 アーキテクチャの概要
UI-TARSは、タスク指示に基づいて観察を受け取り、適切な行動を実行するエージェントです。このプロセスでは、過去のインタラクションの履歴と現在の観察が考慮されます。
4.2 GUI認識の強化
GUI環境の複雑さに対応するため、大規模なデータセットを用い、要素のメタデータを抽出する手法を採用しています。
4.3 統一された行動モデリングとグラウンディング
行動モデルを標準化し、異なるプラットフォーム間での知識の移転を可能にするための統一された行動空間を設計しています。
4.4 推論の注入
複雑な環境における性能向上のため、論理的な意思決定を行う推論能力を強化しています。
4.5 経験からの学習
UI-TARSは、過去のインタラクションから学習し、将来のタスクへの応答を改善します。
5. 実験
5.1 認識能力の評価
UI-TARSの認識能力は、Visual-WebBench、WebSRC、ScreenQAなどのベンチマークを通じて評価され、優れた結果を示しました。
5.2 グラウンディング能力の評価
ScreenSpot Proなどの評価基準を用いて、GUI要素の理解と位置特定能力を評価しました。
5.3 オフラインエージェント能力の評価
静的環境におけるUI-TARSの能力は、Multimodal Mind2WebやAndroid Controlのベンチマークで評価されています。
5.4 オンラインエージェント能力の評価
動的環境での性能は、OSWorldやAndroidWorldで評価され、リアルタイムでの行動の効果が確認されました。
5.5 システム1とシステム2思考の比較
システム1(直感的な反応)とシステム2(意図的な思考)の性能を比較し、システム2が複雑なタスクにおいて特に重要であることが示されました。
6. 結論
本論文では、UI-TARSというネイティブGUIエージェントモデルを提案し、知覚、行動、推論、メモリを統合したフレームワークを構築しました。UI-TARSは、複雑なGUIタスクを最小限の人間の監視で処理できる能力を持ち、将来のGUIエージェントの進化において重要なステップとなることが期待されます。