目次
Evaluating Agent-based Program Repair at Google
この論文は、Googleにおけるエージェントベースのプログラム修復の有効性を評価し、実際のバグの修正に関する実験結果を報告しています。
この論文は、Googleの実際のバグデータを用いて、エージェントベースのプログラム修復手法が産業環境でどの程度効果的に機能するかを実証的に評価し、特に機械報告のバグに対して73%の修復成功率を達成した点が特徴です。
論文:https://arxiv.org/abs/2501.07531
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
エージェントベースのプログラム修復は、現代の大規模言語モデル(LLM)の計画、ツール使用、コード生成能力を組み合わせることで、複雑なバグを自動的にエンドツーエンドで解決することを提供します。最近の研究では、人気のオープンソースのSWE-Benchにおけるエージェントベースの修復アプローチの使用が探求されており、これは高評価のGitHub Pythonプロジェクトからのバグのコレクションです。さらに、SWE-Agentなどのさまざまなエージェント的アプローチがこのベンチマークのバグを解決するために提案されています。
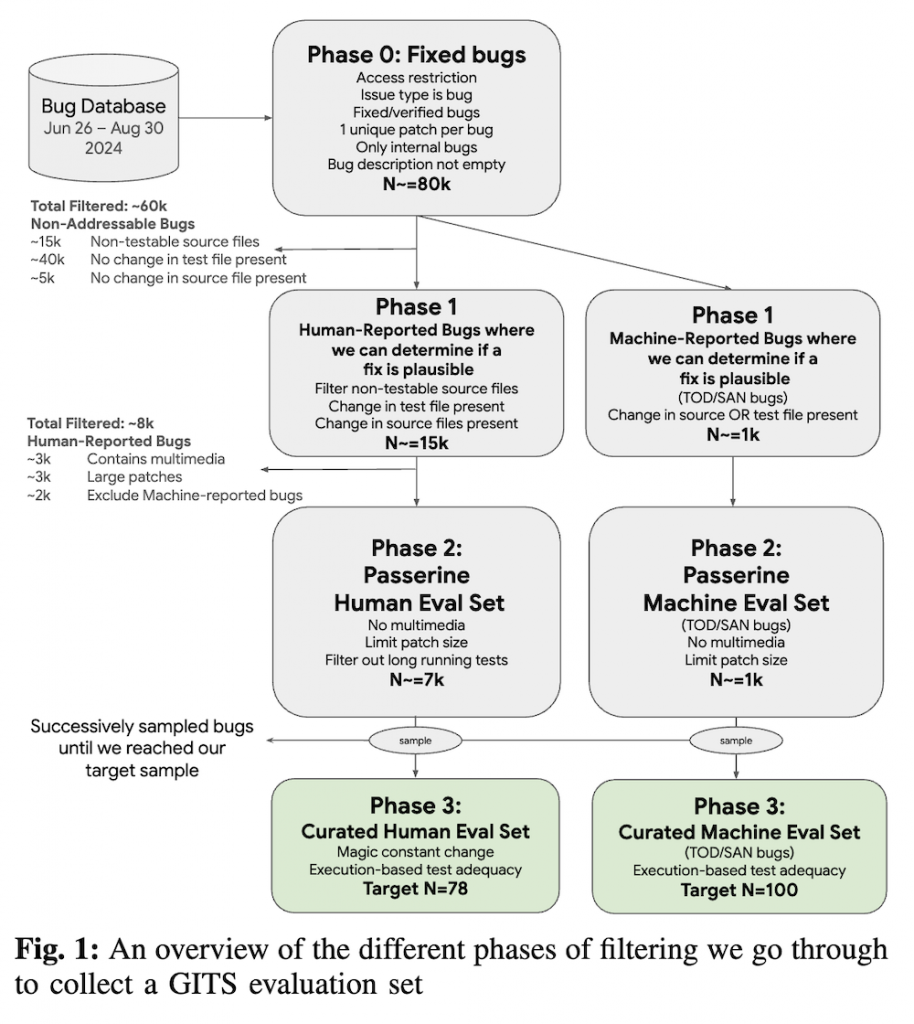
本論文では、エンタープライズコンテキストにおいてバグに対処するためのエージェント的アプローチの実現可能性を探ります。この調査のために、Googleの問題追跡システムから抽出した178のバグを含む評価セットを策定します。このデータセットは、人間報告(78件)と機械報告(100件)のバグの両方を含んでいます。
エージェントベースのプログラム修復の評価
1. 概要
本論文は、エージェントベースのプログラム修復手法が、Googleのエンタープライズ環境においてどの程度有効であるかを探求しています。具体的には、178件のバグを対象にした評価セットを構築し、これには人間によって報告された78件のバグと、機械によって報告された100件のバグが含まれています。これにより、エージェントの修復能力の実務的な有効性を検証しています。
2. 使用した手法
本研究では、SWE-Agentに類似したエージェント「Passerine」を実装しました。このエージェントは、Googleの開発環境内で動作し、プログラム修復のために計画、ツール使用、コード生成の能力を統合しています。具体的には、20のトラジェクトリサンプルとGemini 1.5 Proを用いて、修復パッチを生成しました。Passerineは、評価セット内の機械報告バグに対して73%、人間報告バグに対して25.6%の確率で修正パッチを生成できることが示されています。
3. 実験の詳細
実験の結果、手動での検査を行ったところ、機械報告のバグの43%と人間報告のバグの17.9%について、少なくとも1つのパッチが真のパッチと意味的に等価であることが確認されました。この結果は、SWE-Benchデータセットとは異なる分布を持つバグが含まれており、言語の多様性やサイズ、変更の広がりなどの観点からも異なることが示されています。
4. 結論
本研究は、エージェントベースのプログラム修復手法が実際のエンタープライズ環境での利用において有望であることを示唆しています。この結果は、今後のプログラム修復技術の発展に寄与することが期待され、特にGoogleの環境における実際のバグを対象にした評価は、将来的な研究や開発において重要な基盤を提供します。