目次
Efficient Long Context Language Model Retrieval with Compression
この論文は、長文コンテキスト言語モデルを用いた情報検索において、パッセージ圧縮を通じて検索効率を向上させる新しいアプローチを提案しています。
この論文は、長文コンテキスト言語モデルにおける情報検索の効率を高めるために、圧縮手法を用いて取得性能を6%向上させつつ、コンテキストサイズを1.91倍に圧縮する新しいアプローチを提案しています。
論文:https://arxiv.org/abs/2412.18232
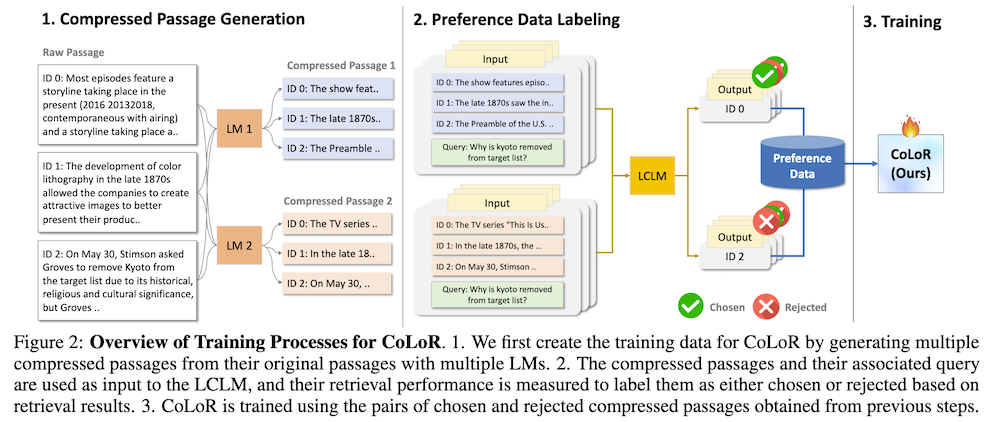
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
長文コンテキスト言語モデル(LCLM)は、情報検索(IR)を行う新しいパラダイムとして登場し、単一のコンテキスト内で全体のコーパスを処理することにより情報の直接的な摂取と取得を可能にし、従来のスパースおよびデンス検索手法を超える可能性を示しています。しかし、取得のために大規模な数のパッセージをコンテキスト内で処理することは計算コストが高く、推論中にそれらの表現を扱うことはさらに処理時間を増加させます。
我々はパッセージ圧縮を用いてLCLMの取得をより効率的かつ効果的にすることを目指します。具体的には、LCLM取得用に特化した新しい圧縮手法を提案し、圧縮されたパッセージの長さを最小化しつつ取得性能を最大化するように訓練されます。これを実現するために、圧縮されたパッセージが自動的に生成され、与えられたクエリに対する取得成功に応じて選択されたか拒否されたかにラベル付けされた合成データを生成し、このデータを用いて長文コンテキスト取得のための圧縮モデル(CoLoR)を好みの最適化で訓練し、簡潔さを強制するために長さ正則化損失を追加します。9つのデータセットに関する広範な実験を通じて、CoLoRは取得性能を6%向上させつつ、コンテキスト内のサイズを1.91倍圧縮することを示します。
効率的な長文コンテキスト言語モデルの検索と圧縮
1. 概要
本論文では、長文コンテキスト言語モデル(LCLM)を用いた情報検索(IR)の新しいアプローチを提案します。LCLMは、従来のスパースおよびデンス検索手法を凌駕する潜在能力を持っていますが、多数のパッセージを処理する際の計算コストや推論時の表現管理に課題があります。このため、LCLMの検索を効率的かつ効果的に行うためのパッセージ圧縮手法を開発しました。
2. 提案手法
提案する圧縮手法は、LCLM検索専用に設計されており、以下の目的を持っています:
- 検索性能を最大化すること
- 圧縮されたパッセージの長さを最小化すること
具体的には、合成データを生成し、圧縮されたパッセージが特定のクエリに対してどのように機能するかに基づいて「選択」または「拒否」としてラベル付けを行います。このプロセスを通じて、効率的なパッセージ生成が実現されます。
3. CoLoRモデルの訓練
「Long context Retrievalのための圧縮モデル」(CoLoR)を用いて、合成データを基に最適化を行います。このモデルは、簡潔さを強化するために長さ正則化損失を追加して訓練されます。これにより、圧縮されたパッセージがより効率的に生成されることを目指しています。
4. 実験結果
本研究では、9つの異なるデータセットを用いて広範な実験が行われました。その結果、CoLoRは検索性能を6%向上させる一方で、コンテキストのサイズを1.91倍圧縮することに成功しました。この成果は、LCLMを用いた情報検索における圧縮技術の重要性を示しています。
5. 結論
本論文は、LCLMによる情報検索における新たなアプローチを提示し、圧縮手法が効率性を向上させる可能性を具体的に示しました。今後の研究において、この手法がさらに多くの応用に展開されることが期待されます。