目次
RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement
この論文は、情報検索を活用して大規模言語モデルの推論能力を向上させる新しいアプローチ「RAG-Star」を提案しています。
RAG-Starは、モンテカルロ木探索を活用して取得した情報を統合し、複雑な推論タスクに対して大規模言語モデルの内在的知識を強化する新しいアプローチを提供します。
論文:https://arxiv.org/abs/2412.12881
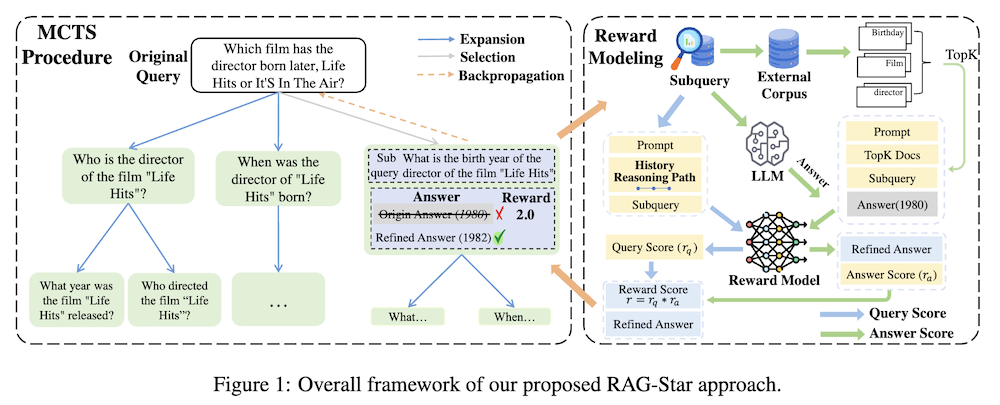
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
既存の大規模言語モデル(LLMs)は優れた問題解決能力を示していますが、複雑な推論タスクには苦労することがあります。連鎖的思考や木構造探索手法の成功にもかかわらず、これらは主にLLMsの内部知識に依存して中間的な推論ステップを検索するため、限られた数の推論ステップを含む単純なタスクを扱うのに制約されています。
本論文では、RAG-Starという新しいRAGアプローチを提案します。これは、取得した情報を統合して、LLMsの内在的な知識に依存した木構造の熟慮推論プロセスを導くものです。RAG-Starはモンテカルロ木探索を活用して、LLM自体に基づく推論のための中間的なサブクエリと回答を繰り返し計画します。内部知識と外部知識を統合するために、クエリおよび回答に配慮した報酬モデルを利用した取得強化検証を提案し、LLMsの内在的推論にフィードバックを提供します。Llama-3.1-8B-InstructおよびGPT-4oを用いた実験により、RAG-Starが従来のRAGおよび推論手法を大幅に上回ることを示しました。
RAG-Star: 検索強化による熟考的推論の向上
1. 研究の背景と目的
既存の大規模言語モデル(LLM)は、問題解決能力に優れていますが、複雑な推論タスクにおいては限界があります。特に、連鎖的思考や木構造探索における成功事例は、これらのモデルが内部知識に依存しており、シンプルなタスクに対する推論ステップに制約があります。このような背景を踏まえ、本論文ではRAG-Starという新たなアプローチを提案し、推論の精度を向上させることを目指します。
2. RAG-Starの提案
RAG-Starは、取得した情報をもとに木構造の熟考的推論プロセスを導く手法です。このアプローチでは、モンテカルロ木探索(MCTS)を利用して、LLM自身に基づいて中間的なサブクエリと回答を計画的に生成します。これにより、内部知識と外部知識を効果的に統合できるようになります。
3. 方法論
RAG-Starの中心的な機能は、検索強化型検証です。これは、クエリおよび回答に対する報酬モデリングを活用し、LLMの推論能力にフィードバックを提供することを目的としています。この手法により、推論の精度が向上し、より複雑なタスクに対しても対応可能となります。
3.1 実験設計
本研究では、Llama-3.1-8B-InstructとGPT-4oという二つのLLMを用いて、RAG-Starの性能を評価しました。実験は、RAG-Starがどのように内在的および外部知識を統合し、問題解決に至るかを観察するために設計されました。具体的には、性能を推論の正確性、計算の効率性、そして取得した情報の活用に基づいて評価します。
4. 実験結果
実験の結果、RAG-Starは従来のRAG手法や推論手法に対して顕著に優れた性能を示しました。特に、複雑な推論タスクにおいて取得した情報を効果的に活用し、推論能力を向上させることが確認されました。これにより、RAG-Starの有効性が実証され、今後の研究の可能性が広がります。
5. 結論
RAG-Starは、LLMの熟考的推論を強化するための新たなアプローチを提供し、内部と外部の知識を統合することで推論の精度を高めることが示されました。今後の研究において、さらに多様なタスクへの適用が期待されます。