目次
The BrowserGym Ecosystem for Web Agent Research
この論文は、ウェブエージェントの研究を効率的に評価・ベンチマークするための「BrowserGym」エコシステムを提案し、複数の最先端大規模言語モデルの性能を比較した結果を示しています。
BrowserGymエコシステムは、ウェブエージェントの評価を統一された環境で行うことで、異なるベンチマーク間の比較を容易にし、再現可能な結果を提供することを目指しており、特に大規模言語モデルの性能を一元的に評価する新たなプラットフォームを創出しています。
論文:https://arxiv.org/abs/2412.05467
リポジトリ:https://github.com/ServiceNow/BrowserGym
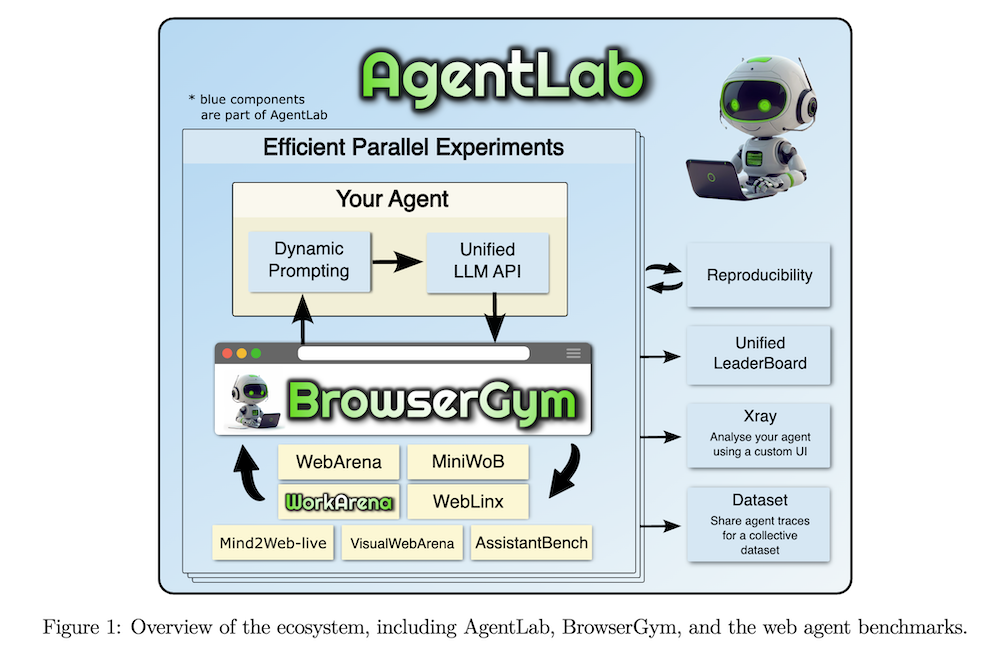
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
BrowserGymエコシステムは、特に自動化や大規模言語モデル(LLM)を利用したウェブインタラクションタスクのためのウェブエージェントの効率的な評価とベンチマーキングのニーズに応えるものです。既存のベンチマークの多くは、断片化と一貫性のない評価手法に悩まされており、信頼できる比較や再現可能な結果を達成するのが困難です。
BrowserGymは、明確に定義された観察空間とアクション空間を持つ統一されたジムのような環境を提供することで、これを解決することを目指しています。多様なベンチマークにわたる標準化された評価を促進し、新しいベンチマークの統合を容易にする補完的なフレームワークであるAgentLabと組み合わせることで、BrowserGymはウェブエージェントの開発を支援し、より信頼性の高い比較を可能にし、エージェントの行動の詳細な分析を促進する柔軟性を提供します。この標準化されたアプローチは、ウェブエージェントの開発にかかる時間と複雑さを軽減し、最終的には、LLM駆動の自動化における革新を加速する結果につながる可能性があります。
証拠として、私たちは初の大規模なマルチベンチマークウェブエージェント実験を実施し、BrowserGymで現在利用可能なすべてのベンチマークで6つの最先端のLLMのパフォーマンスを比較しました。その他の発見の中で、私たちの結果は、OpenAIとAnthropicの最新モデルの間に大きな不一致があることを浮き彫りにし、Claude-3.5-Sonnetがほぼすべてのベンチマークで優位に立っている一方で、視覚関連タスクではGPT-4oが優れていることを示しています。これらの進展にもかかわらず、私たちの結果は、実世界のウェブ環境の固有の複雑さと現在のモデルの限界により、堅牢で効率的なウェブエージェントを構築することが依然として大きな課題であることを強調しています。
1. BrowserGymエコシステムによるWebエージェント研究
1.1 はじめに
近年、大規模言語モデル(LLMs)や視覚言語モデル(VLMs)の発展により、対話型アシスタントの能力が大幅に向上しました。特に、ユーザーの代わりにウェブブラウザ内でタスクを自動化する能力が注目されており、これによりユーザーは高次の意思決定に集中できるようになります。
1.2 研究の背景
自律エージェントの研究は学術界と産業界で重要視されており、LLMsを活用したエージェントの研究が急増しています。この論文では、既存のベンチマークの断片化を解消し、信頼性のある比較を可能にするための統一フレームワークであるBrowserGymを提案しています。
2. 背景と関連研究
2.1 Webエージェントベンチマーク
Webエージェントの性能を評価するためのベンチマークは急速に進化しています。初期のベンチマーク(例:MiniWoBやWebShop)から、より複雑なシナリオを評価するための新しいベンチマーク(例:Mind2Web)まで、多岐にわたります。
2.2 Webエージェントの実装
Webエージェントの実装方法は、HTML要素との直接的なインタラクションや、視覚言語モデルを利用したアプローチに分かれ、それぞれ異なる能力を持っています。
3. BrowserGym
3.1 観察空間の拡充
BrowserGymは、タスクの目標、オープンしたタブのリスト、現在のページの内容を含む豊富な観察空間を提供します。DOMやAXTreeを利用し、ページの構造を把握することが可能です。
3.2 行動空間の拡張
エージェントは、Pythonコードを用いて様々なアクションを実行できます。この行動空間は、ユーザーが定義したアクションマッピングを通じてカスタマイズ可能です。
3.3 拡張性
新しいタスクを簡単に作成できるように設計されており、タスクの初期状態を設定するsetupメソッドと、タスクの完了を検証するvalidateメソッドを実装するだけで済みます。
4. Webエージェントベンチマークの統一
BrowserGymは、MiniWoB(++)、WebArena、VisualWebArena、WorkArenaなどの複数のベンチマークをサポートしており、統一されたインターフェースを提供しています。これにより、異なるベンチマーク間での一貫した評価が可能です。
5. AgentLab
5.1 実験の実行
AgentLabは、BrowserGym上でエージェントの実験を簡素化するためのツールセットです。Studyオブジェクトを使って、複数のエージェントの実験を整理し、並行して実行できます。
5.2 並行実験
大量のエピソードに対して並行処理を行うために、RayやJoblibなどのバックエンドを利用し、効率的な評価を実現します。
5.3 AgentXRay
エージェントの行動を詳細に分析するためのインターフェースを提供し、エージェントの選択したアクションを視覚化し、決定過程を検証可能です。
6. 実験
6.1 実験の設定
GenericAgentを使用して、BrowserGymエコシステム内のすべてのベンチマークで評価を行います。実験の設定は、多様な環境でのエージェントのパフォーマンスを測定することを目的としています。
6.2 結果
実験の結果、Claude 3.5 Sonnetがほとんどのベンチマークで最高のパフォーマンスを示し、特にWorkArena L2ベンチマークでは39.1%の成功率を記録しました。
7. 議論
BrowserGymエコシステムは、Webエージェント研究の標準化を促進し、再現性や一貫性を高める基盤を提供します。これにより、LLM駆動の自動化の進展が加速することが期待されます。
8. 今後の展望
安全性評価やリアルタイムでのWebエージェントの開発、効率的なLLMsの開発が今後の重要な課題として挙げられます。これにより、Webエージェントはより多様なタスクに対応し、ユーザー体験を向上させることが期待されます。
付録
A. BrowserGymの高レベルアクションセット
エージェントが使用可能なアクションのリストと具体的な使用例を提供します。
B. ベンチマークの詳細な説明
各ベンチマークの概要と特性を記載しています。
C. 例示的なプロンプト
エージェントの実装におけるプロンプトの例を示し、Dynamic Promptingの使用方法について説明します。