目次
xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
この論文は、リトリーバル強化生成のための極端な文脈圧縮手法「xRAG」を提案し、ドキュメント埋め込みを言語モデルに統合することで、圧縮率を向上させながら計算効率を改善することを示しています。
xRAGは、検索強化生成における極端なコンテキスト圧縮を実現し、リトリーバーと言語モデルを固定したまま、モダリティブリッジを介して高い圧縮率を保ちながらも10%以上の性能向上を達成する新しいアプローチを提供します。
論文:https://arxiv.org/abs/2405.13792
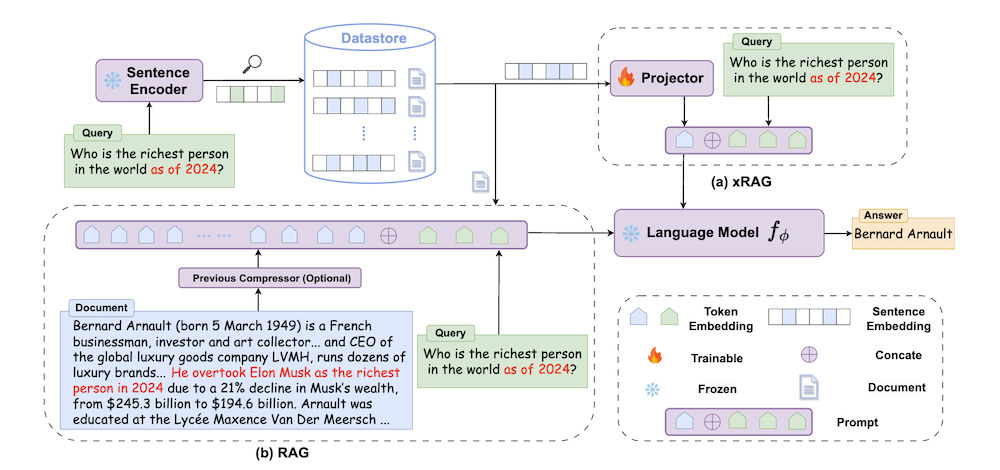
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
この論文では、情報検索を強化するための革新的なコンテキスト圧縮手法「xRAG」を紹介します。xRAGは、従来の情報検索でのみ使用されていた文書埋め込みを、検索モダリティからの特徴として再解釈します。モダリティ融合手法を用いることで、xRAGはこれらの埋め込みを言語モデルの表現空間にシームレスに統合し、テキストの対応物を必要とせず、極端な圧縮率を実現します。
xRAGでは、トレーニング可能なコンポーネントはモダリティブリッジのみであり、リトリーバーと言語モデルは固定されたままとなります。この設計選択により、オフラインで構築された文書埋め込みを再利用でき、検索強化のプラグアンドプレイ特性が保持されます。実験結果は、xRAGが6つの知識集約型タスクで平均10%以上の改善を達成し、密な7Bモデルから8x7B Mixture of Experts構成に至るさまざまな言語モデルバックボーンに適応可能であることを示しています。
xRAGは、以前のコンテキスト圧縮手法を大幅に上回るだけでなく、いくつかのデータセットにおいて非圧縮モデルの性能に匹敵し、全体的なFLOPsを3.53倍削減します。我々の研究は、モダリティ融合の観点から検索強化生成における新しい方向性を切り開くものであり、今後の効率的でスケーラブルな検索強化システムの基礎を築くことを期待しています。
1. はじめに
1.1 研究の背景と目的
本論文では、リトリーバル拡張生成(RAG)に特化した新しいコンテキスト圧縮手法「xRAG」が提案されています。xRAGは、情報検索に基づく生成モデルの効率性を高め、従来の手法の限界を克服することを目指しています。特に、文書埋め込みをリトリーバルモダリティの特徴として再解釈し、生成タスクへの適用を効率化します。
1.2 研究の重要性
従来の手法では文書埋め込みが情報検索のために使用され、生成モデルに直接利用されることはありませんでした。xRAGは、文書埋め込みを有効活用する新たな方法論を提供し、生成タスクにおけるパフォーマンス向上を図ります。
2. 方法論
2.1 モダリティ融合
xRAGの中心的なアイデアは、モダリティ融合手法を用いて文書埋め込みを言語モデルの表現空間に統合することです。このアプローチにより、テキスト表現を必要とせず、極限的な圧縮率を実現します。
2.2 トレーニング構造
xRAGでは、唯一の訓練可能なコンポーネントとして「モダリティブリッジ」を導入し、リトリーバーおよび言語モデルは固定されたままにします。この設計により、オフラインで構築された文書埋め込みが再利用でき、リトリーバルの拡張性が維持されます。
3. 実験
3.1 実験設定
xRAGの性能を評価するために、6つの知識集約型タスクにおいて実験を行いました。対象とした言語モデルは、7Bの密なモデルから8x7BのMixture of Experts構成まで多岐にわたります。
3.2 成果
実験結果において、xRAGは既存のコンテキスト圧縮手法を大幅に上回るパフォーマンスを示し、いくつかのデータセットでは非圧縮モデルと同等の結果を達成しました。具体的には、全体のFLOPsを3.53倍削減しながら、平均で10%以上の性能改善を実現しています。
4. 結論
本研究は、リトリーバル拡張生成の新たな方向性を提供し、今後の効率的かつスケーラブルなシステムの基盤を築くことを目指しています。xRAGの手法は、情報検索を基にした生成モデルの進化に寄与するものと期待されます。