目次
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
この論文は、文書画像認識における大規模マルチモーダルモデルの能力を評価するための包括的で挑戦的なOCRベンチマーク「CC-OCR」を提案しています。
CC-OCRは、実際のアプリケーションから得られた多様な画像データを41%含む39のサブセットを持ち、LMMのリテラシー能力を多角的に評価する初の包括的なOCRベンチマークである点が特徴です。
論文:https://arxiv.org/abs/2412.02210
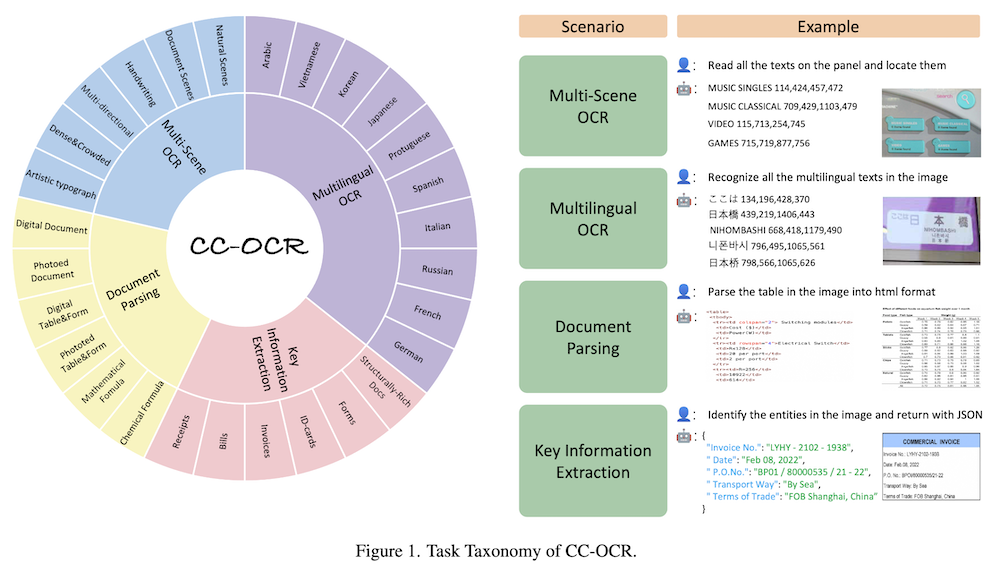
以下は、LLMを用いてこの論文の内容を要約したものになります。
概要
大規模マルチモーダルモデル(LMM)は、自然言語の指示を用いた文書画像の認識において印象的な性能を示しています。しかし、リッチな構造と細かな視覚的課題を伴うリテラシーにおける能力がどの程度であるかは不明です。現在の状況では、LMMのリテラシー能力を効果的に測定する包括的なベンチマークが不足しています。既存のベンチマークは、狭いシナリオや特定のタスクに制限されていることが多いです。
この目的のために、私たちはCC-OCRという包括的なベンチマークを導入します。CC-OCRは、多様なシナリオ、タスク、課題を持っています。CC-OCRは、マルチシーンテキスト読み取り、多言語テキスト読み取り、文書解析、重要情報抽出の4つのOCR中心のトラックで構成されています。39のサブセットと7,058の完全に注釈された画像を含み、その41%は実際のアプリケーションから得られたもので、初めて公開されます。
さらに、私たちは9つの著名なLMMの評価を行い、これらのモデルの強みと弱み、特にテキストのグラウンディング、多方向性、および繰り返しの幻覚に関する課題を明らかにしました。CC-OCRは、OCR中心のタスクにおけるLMMの能力を包括的に評価し、LMMの進展を促進することを目指しています。
以下は、提供された情報に基づいて作成したCC-OCRに関する解説記事です。この論文は、大規模マルチモーダルモデル(LMM)のリテラシー能力を評価するための新しいベンチマークを提案しています。
CC-OCR: 大規模マルチモーダルモデルのリテラシー評価のための包括的かつ挑戦的なOCRベンチマーク
1. はじめに
1.1 研究の背景
文書画像認識において、LMMは自然言語の指示に基づく優れた性能を示しています。しかし、これらのモデルが持つリテラシー能力、特に複雑な視覚的課題や構造を理解する能力については、明確な評価基準が不足しています。
1.2 目的
CC-OCRは、これらの欠点を克服するために設計されており、多様なシナリオやタスクを含む包括的なベンチマークを提供します。これにより、モデルのリテラシー能力を効果的に測定することを目指しています。
2. CC-OCRの概要
2.1 ベンチマークの構成
CC-OCRは、以下の4つの主要なトラックから成り立っています:
- マルチシーンテキストリーディング: 異なる背景や文脈でのテキスト認識
- 多言語テキストリーディング: 様々な言語のテキストを認識する能力
- 文書解析: 文書の構造を理解し、重要な情報を抽出する能力
- 重要情報抽出: 文書から特に重要な情報を特定し、抽出する能力
これらのトラックは、39のサブセットと7,058枚の完全に注釈された画像を含み、41%は実際のアプリケーションから収集されたデータです。
3. 実験方法
3.1 モデルの評価
本研究では、9つの著名なLMMを評価しました。評価においては、テキストのグラウンディング、マルチオリエンテーション、繰り返しの幻覚といった観点から、各モデルの強みと弱みが分析されました。
3.2 評価基準
評価には、正確性、再現率、F1スコアといった標準的な指標が用いられ、モデルのリテラシー能力が定量的に測定されました。
4. 結果と考察
4.1 評価結果
評価の結果、各LMMのパフォーマンスには顕著な違いが見られました。特に、テキストの位置特定能力やマルチオリエンテーションの処理において、モデルごとに異なる能力が明らかになりました。
4.2 今後の課題
CC-OCRは、リテラシー能力の新たな評価基準を提供しており、今後の研究における重要な指針となることが期待されます。特に、現実のアプリケーションに即したデータセットを使用することで、モデルの実用性を向上させる可能性があります。
5. 結論
CC-OCRは、LMMのリテラシー能力を包括的に評価するための新しいベンチマークとして、今後の研究や実用的な応用に向けた重要なステップを提供します。このベンチマークが、リテラシー関連のタスクにおけるモデルの性能向上に寄与することが期待されます。