目次
DocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
この論文は、ユーザーのリクエストに基づいて文書の構造を編集するための新しいフレームワーク「DocEdit-v2」を提案し、マルチモーダル大規模モデルを活用してドキュメントの編集精度を向上させる手法を示しています。
論文:https://arxiv.org/abs/2410.16472
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
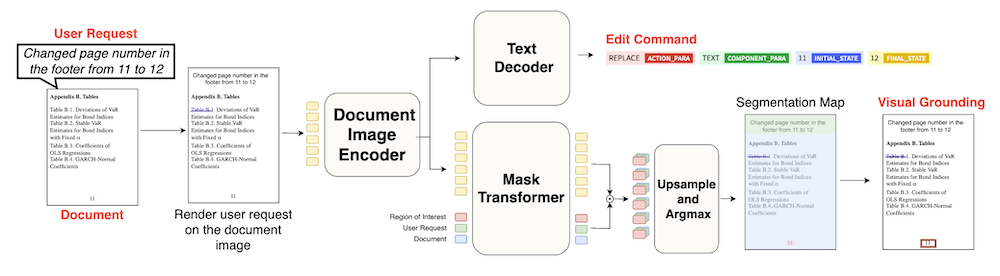
この論文では、ユーザーの要求に基づいて文書画像内のテキスト、視覚、およびレイアウトコンポーネントを操作する新しいフレームワーク「DocEdit-v2」を提案しています。DocEdit-v2は、ユーザーの編集要求を視覚的に基づいて正確なコマンドに変換する「Doc2Command」モジュールと、生成されたコマンドを大規模マルチモーダルモデル向けに再構成する「Command Reformulation」を利用しています。このフレームワークは、GPT-4VやGeminiなどのLMMを活用して文書のHTML構造を編集し、最終的な文書画像を生成します。実験により、DocEdit-v2はコマンド生成や領域の検出、全体的な文書編集タスクにおいて従来の手法を大幅に上回る性能を示しました。これにより、ユーザーの要求に応じた効率的な文書編集が可能となります。
DocEdit-v2は、ユーザーの編集要求を視覚的に解釈し、精密なコマンド生成と再構成を実現することで、HTML構造の編集をより直感的かつ効率的に行うことができる点が革新的です。
DocEdit-v2における文書編集のためのマルチモーダルフレームワーク
1. はじめに
デジタル文書は、コミュニケーションや情報配信、業務生産性の向上において重要な役割を果たしています。文書編集は、ユーザーの要求に応じてテキストや視覚的要素、構造を変更するプロセスであり、具体的には空間的配置、要素の置換、サイズ変更、特別効果の適用などが含まれます。
2. 関連研究
従来の研究では、自然画像データセットに焦点が当てられ、文書特有のテキストリッチなコンテンツや構造化された要素の多様性が考慮されていなかったため、効果的な局所的編集や間接的な参照が欠如しています。
3. DocEdit-v2の方法論
DocEdit-v2は、ユーザーの要求を文書画像内で正確に特定し、編集コマンドに変換するために以下の三つの主要コンポーネントを使用します。
- Doc2Command: ユーザーのリクエストを具体的なアクションに変換し、文書画像内の関心領域を特定します。このモデルは、多タスク・マルチモーダルなTransformerに基づいています。
コマンド再構成プロンプティング: Doc2Commandで生成された編集コマンドを一般的な大規模マルチモーダルモデル(LMM)向けに調整します。
生成的文書編集: HTMLとCSSを使用して文書を構造化し、生成的手法を用いて文書編集を行います。
4. 文書編集評価
文書の編集後は、自動評価指標(DOMツリー編集距離、CSS IoU)と人間による評価(スタイル再現性、コンテンツ再現性、編集の正確性)を用いて、編集された文書の品質を評価します。
5. 実験設定
実験はDocEdit-PDFデータセットを使用し、17808の文書画像と対応するユーザー編集リクエストから構成され、訓練、テスト、検証セットに分けられます。
6. ベースライン
コマンド生成、視覚グラウンディング、文書編集の各タスクに対するパフォーマンスベンチマークを確立し、DocEdit-v2の性能を評価します。
7. 結果
DocEdit-v2は、コマンド生成タスクにおいて86.1%の認識精度を達成し、従来技術を上回る結果を示しました。特に、Doc2Commandモジュールがユーザーのリクエストに基づいて正確なコマンドを生成する能力を大いに向上させました。
8. 結論
DocEdit-v2は、ユーザーの要求を理解し、文書画像内の編集を効果的に実行するための新しいアプローチを提供します。今後の研究では、多様な文書タイプへの適応性の向上を目指します。
9. 倫理声明
研究では、公開されているDocEdit-PDFコーパスを使用し、新たな注釈を導入することなく、プライバシーに配慮して実験を実施しました。
10. 制限事項
- DocEdit-v2はHTMLとCSSを用いた文書を生成しますが、複雑な視覚要素の生成には制限があります。
- LMMのAPI使用に伴うコストや性能の変動も考慮されています。
付録
付録では、実験結果の例やプロンプトテンプレート、追加評価指標、計算リソース、評価手順について詳しい情報が提供されています。