目次
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
この論文は、自動回帰モデルからの適応によって拡張された拡散言語モデルを提案し、その性能を評価している研究です。
論文:https://arxiv.org/abs/2410.17891
リポジトリ:https://github.com/HKUNLP/DiffuLLaMA
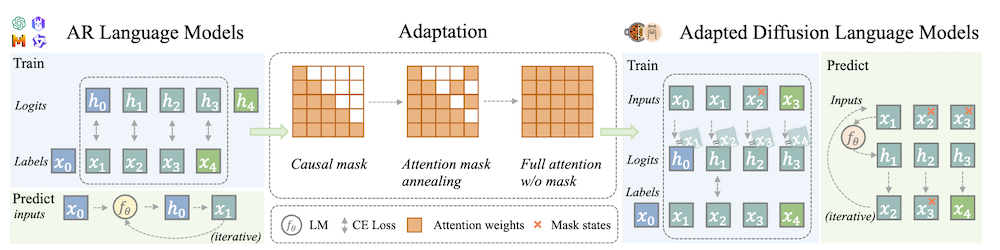
以下は、LLMを用いてこの論文の内容を要約したものになります。
要約
この論文では、拡散言語モデル(DLM)が自己回帰モデル(AR)の適応を通じてスケーリングされる可能性について検討しています。著者たちは、ARモデルとDLMの間の関連性を示し、ARモデルを利用してテキストの拡散モデルを構築する新しいアプローチを提案しています。実験の結果、DiffuGPTおよびDiffuLLaMAというDLMが、ARモデルに匹敵するかそれ以上の性能を発揮することが確認されました。特に、これらのモデルは流暢なテキスト生成や文脈内学習の能力を持ち、指示に従う能力も示しています。最終的に、著者たちはこのアプローチが次世代の言語モデルの開発において重要な意味を持つと結論付けています。
この論文の特徴は、既存の自己回帰モデルを利用して拡散言語モデルを効果的に構築し、流暢なテキスト生成や文脈内学習において従来のモデルを上回る性能を実現した点です。
以下は、提供された情報を基にした論文の解説です。各章ごとに内容をまとめて説明します。
1. はじめに
1.1 背景
大規模言語モデル(LLM)は、質の高いテキスト生成や文脈内学習能力を示し、人工知能の新たな時代を切り開いています。これらの進展は主に自己回帰(AR)モデルのスケーリングによるものですが、ARモデルには未来の計画能力や自己修正能力に限界が存在します。これに対処するため、拡散言語モデル(DLM)が提案されており、特に制御可能なテキスト生成の可能性に注目が集まっています。
1.2 目的
本研究の目的は、ARモデルを適応させることでDLMを構築し、言語モデリングのベンチマークでの公正な比較を行うことです。127Mから7BパラメータのARモデルを基に、DiffuGPTとDiffuLLaMAというモデルを生成しました。
1.3 概要
DiffuGPTとDiffuLLaMAは、200Bトークン未満でトレーニングされ、従来のDLMやARモデルと比較して優れた性能を示しました。特に、情報を埋め込むタスクや数学的推論能力において強みを持っています。
2. 前提知識と記法
2.1 拡散モデルの概要
拡散モデルは、データ分布に従う変数 \(x_0\) と、そのノイズを含む変数 \(x_t\) を用いて、前向き過程と後向き過程を定義します。前向き過程では、初期データを徐々にノイズに変換し、後向き過程ではノイズを除去して元のデータを再構成します。
2.2 数学的表現
拡散モデルの前向き過程は、時刻ごとの確率分布を用いて定義され、逆向き過程はノイズを除去する方法を示します。
3. モデル
3.1 連続時間の離散拡散過程
連続時間の離散拡散プロセスを定式化し、ARモデルとの接続を確立しています。これにより、ARモデルの訓練目的と拡散モデルの目的を統一し、ARからDLMへの適応を可能にしています。
3.2 適応手法
- 注意マスクアニーリング: ARモデルの因果的マスクを段階的に全体的な注意マスクに変換します。
- シフト操作: ARモデルの出力ロジットを次のトークンに合わせて調整します。
- タイムエンベディングなし: ARモデルに基づくDLMを設計し、追加のパラメータを避けます。
3.3 サンプリング手法
全トークンをマスクで初期化し、逆過程に従ってトークンを生成します。
4. 実験
4.1 適応設定
DiffuGPTはFineWebデータセットから、DiffuLLaMAはSlimPajamaとStarcoderの混合データを使用してトレーニングされました。
4.2 評価設定
モデルの性能は、TriviaQAやLambadaなどの多様なタスクを通じて評価され、従来の評価基準だけでなく、広範なベンチマークを用いて分析されています。
4.3 言語モデリング能力
DiffuGPTとDiffuLLaMAはARモデルに対して優れた性能を発揮し、特に情報を埋め込むタスクや数学的推論において強みを示しました。
5. 関連研究
既存のDLMおよびARモデルに関する文献をレビューし、特に拡散モデルの適応に関する先行研究との関連性を示しています。非自動回帰生成の研究も含まれ、トークン生成の制約を解放する新たな能力が強調されています。
6. 結論
本研究では、ARモデルからの適応を通じてDLMのスケーリングを実現する手法を提案しました。DiffuGPTおよびDiffuLLaMAは、言語モデリングの性能を改善し、さらなる研究の基盤を提供します。将来的には指示に基づく調整や推論時の計画手法の探索が予定されています。
付録
A. 目的の導出
拡散モデルの前向き過程と後向き過程の詳細な導出が行われています。
B. 実装の詳細
モデルのトレーニングデータやハイパーパラメータ、評価設定について詳述されています。
C. 追加結果
無条件生成や他のタスクに関する追加の結果が提供され、モデルの性能を評価するための詳細な情報が含まれています。
このように、論文はARモデルからの適応を通じてDLMの性能を向上させる新たな方法論を提示しており、今後の研究において重要な貢献を果たすことが期待されます。