目次
Infinity Parser: Layout Aware Reinforcement Learning for Scanned Document Parsing
この論文は、レイアウトを意識した強化学習フレームワークを用いて、スキャンした文書を高精度で解析する新しい手法「Infinity Parser」を提案しています。
この論文の特徴は、従来のエラー伝播の問題を克服し、多様なレイアウトの文書を高精度で解析するために、レイアウトを意識した強化学習を用いた新しいフレームワーク(layoutRL)を導入し、実世界のデータと合成データを組み合わせた大規模なデータセット(Infinity-Doc-55K)を活用している点です。
論文:https://arxiv.org/abs/2506.03197
リポジトリ:https://github.com/infly-ai/INF-MLLM/tree/main/Infinity-Parser

以下は、弊社AI開発ツール「IXV」を用いてこの論文を要約したものです。見出しや章立てが元論文とは異なる場合があります。
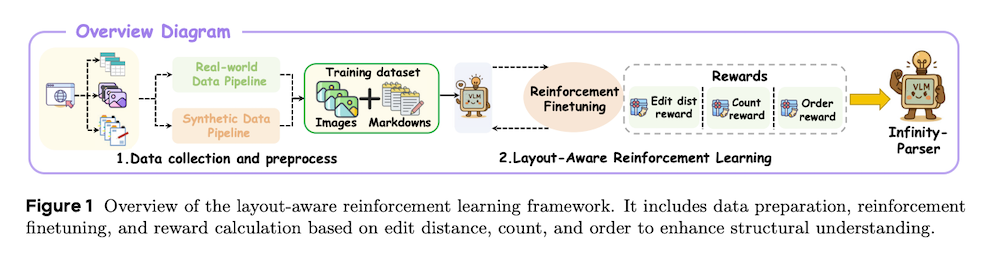
概要
スキャンされた文書を豊富な構造を持つ機械可読形式に自動的に解析することは、文書AIにおける重要なボトルネックであり、従来の多段階パイプラインはエラー伝播や多様なレイアウトへの適応性の限界に悩まされています。我々は、レイアウトを意識した強化学習フレームワークであるlayoutRLを提案し、正規化された編集距離、段落数の精度、読み順の保持という複合報酬を最適化することで、モデルが明示的にレイアウトを認識するようにトレーニングします。
我々が新たに公開するデータセット「Infinity-Doc-55K」は、55Kの高忠実度の合成スキャン文書解析データと専門家によってフィルタリングされた実世界の文書を組み合わせたものであり、これを用いて、Vision-Languageモデルに基づくパーサーであるInfinity-Parserを実装します。OCR、表や数式の抽出、読み順検出のための英語および中国語のベンチマークで評価した結果、Infinity-Parserは精度と構造の忠実性において新たな最先端のパフォーマンスを達成し、専門的なパイプラインや汎用のビジョン・ランゲージモデルを上回る結果を示しました。私たちは、頑健な文書理解の進展を加速させるために、コードとデータセットを公開する予定です。
1. 導入
スキャンされた文書のリッチな構造化機械可読フォーマットへの自動解析は、従来の多段階パイプラインがエラー伝播と多様なレイアウトへの限定的適応性に悩まされているため、Document AIにおける重要なボトルネックである。本研究では、正規化編集距離、段落数精度、読み順保存を組み合わせた複合報酬を最適化することで、モデルを明示的にレイアウト認識させるend-to-end強化学習フレームワークlayoutRLを提案する。新たにリリースしたデータセット「Infinity-Doc-55K」を活用し、55K件の高忠実度合成スキャン文書解析データとエキスパートフィルタリングされた実世界文書を組み合わせ、Infinity-Parserというビジョン言語モデルベースのパーサーでlayoutRLを実装した。
2. 方法論
2.1 Infinity-Doc-55Kと生成パイプライン
55,066件のリッチに注釈付けされた文書からなる大規模マルチモーダルデータセット「Infinity-Doc-55K」を構築した。従来のベンチマークが単独のサブタスクを対象とするのに対し、このデータセットはレンダリングされたスキャン文書ページと対応するMarkdown表現を組み合わせることで、脆弱な多段階パイプラインに依存せずに視覚入力を直接レイアウト出力に変換するモデルの訓練と評価を可能にする。合成データパイプラインと実世界データパイプラインの二重構造により、注釈品質と構造的多様性のバランスを実現している。
2.2 レイアウト認識報酬による強化学習
GRPO(Group Relative Policy Optimization)を用いた強化学習フレームワークを採用し、構造的忠実度と意味的精度を向上させる。多面的報酬RMulti-Aspectは三つの補完的な構成要素から成る:(1)編集距離報酬Rdist:正規化Levenshtein距離に基づく、(2)カウント報酬Rcount:段落数の精度を測定、(3)順序報酬Rorder:読み順の保存を評価。最終的な多面的報酬は、ハンガリアンアルゴリズムによる最適マッチングに基づいて、これら三つの要素の重み付き組み合わせとして計算される。
3. 実験
Qwen2.5-VL-7BモデルをVerlベースの分散訓練環境でGRPOを用いてファインチューニングした。8台のA100 GPU(80GB)を使用し、KL係数β=1.0×10^-2、各問題インスタンスに対して8つの応答をサンプリング(最大長8192トークン、温度1.0)、ロールアウトバッチサイズとグローバルバッチサイズを128に設定した。AdamWオプティマイザー(β1=0.9、β2=0.99)、学習率1.0×10^-6で1エポック訓練を実施した。
3.1 評価と指標
OmniDocBench、Fox、PubTabNet、FinTabNetなどの英語・中国語ベンチマークで評価を実施。純粋テキストには正規化編集距離(NED)、テーブルにはTEDSとNED、数式にはCDM、NED、BLEU、読み順にはNEDを使用した。olmOCR-Benchも含め、多様な文書構造に対する包括的な評価を行った。
3.2 主要結果
OmniDocBenchでの包括的評価では、Infinity-Parser-7Bが全てのサブタスクと言語において最もバランスの取れた性能を達成し、テーブル認識で新たなSOTA結果を記録しつつ、テキスト、数式、読み順抽出で競争力のある精度を維持した。PubTabNetとFinTabNetでのテーブル認識評価では、Infinity-Parser-7BがTEDS-SとTEDSスコアで最高値を達成(PubTabNet: 91.90/89.25、FinTabNet: 97.25/96.47)した。
3.3 アブレーション研究
データ有効性の影響、データ構築手法、多面的報酬について分析した。SFTパラダイムは一定の規模を超えると構造的精度を維持できないが、レイアウト認識報酬を持つ強化学習は構造的モデリング能力を向上させることを確認した。合成データと実世界データの組み合わせがRL設定で最良の性能を発揮し、距離ベースの報酬に加えてカウントと順序報酬を導入することで構造的一貫性が大幅に改善された。
3.4 結果分析
ゼロショットモデルは主要な構造要素を捉えられずタイトルを省略し冗長または不完全なコンテンツを生成するが、SFTでは一般的なレイアウトを識別できるものの記号レベルのエラーと重複出力に悩まされる。対照的に、レイアウト認識RLモデルは最も正確で一貫性のある結果を示し、文書階層を成功裏に保持し冗長性を排除している。Infinity-Parserは学術論文、書籍、教科書、試験、雑誌、新聞など幅広い文書タイプでベースラインを一貫して上回る性能を示した。
4. 関連研究
4.1 言語モデルのための強化学習
OpenAIのGPTシリーズ、DeepSeek-R1、Geminiなどの大規模言語モデルの最近の進歩は、推論能力向上における強化学習の重要な可能性を浮き彫りにしている。このRLパラダイムは、コード生成、自律的ツール利用、情報検索などの高度な推論を要求する他のドメインにも成功裏に拡張されている。視覚言語モデル(VLMs)の領域でも、精密なオブジェクト計数、微妙な視覚認識、複雑なマルチモーダル推論においてRLの有効性が実証されている。
4.2 VLMベースの文書解析
文書理解と光学文字認識(OCR)における最近の進歩は、視覚言語モデル(VLMs)の知覚能力を評価する重要なベンチマークとしてその重要性を浮き彫りにしている。GPT-4oやQwen2-VLなどのモデルは、事前訓練中に大規模OCRコーパスを組み込むことで文書コンテンツ抽出タスクで競争力のある性能を達成している。VLMsの出現により、Donut、Nougat、Kosmos-2.5、Vary、mPLUG-DocOwl、Fox、GOTなどのモデルがend-to-end文書解析の進歩をさらに加速させている。
5. 結論
本研究では、正規化編集距離、段落数精度、読み順保存を組み合わせた多面的報酬を最適化することで、文書パーサーを明示的にレイアウト認識させる初のend-to-end強化学習フレームワークlayoutRLを提案した。この訓練パラダイムをサポートするため、高忠実度合成スキャン文書解析データとエキスパートフィルタリングされた実世界サンプルを組み合わせた55K文書コーパス「Infinity-Doc-55K」をリリースした。layoutRLを活用したInfinity-Parserは、OCR、テーブル・数式抽出、読み順検出を含む英語・中国語タスクでend-to-endモデル間の新たなSOTA性能を達成している。